
I’ve written before (here and here —yes, not quite a decade ago!) about the need for a tool to collect data for my work in sound system analysis (phonology). This year, I decided to stop waiting for someone else to do this for me. So learned Python and Tkinter, and I now have a draft tool, that I’m going to try out in a live work environment next week. Here is a screenshot of the splash screen:

The database it refers to is a Lexical Interchange FormaT (LIFT) database, which allows collaboration with those using other tools that can read LIFT (e.g., FLEx, WeSay, and LexiquePro), as well as archiving online (e.g. at languagedepot.org). Once it loads (1.5 sec, unless it takes 3 minutes to reanalyze syllable profiles), you get the following status field:
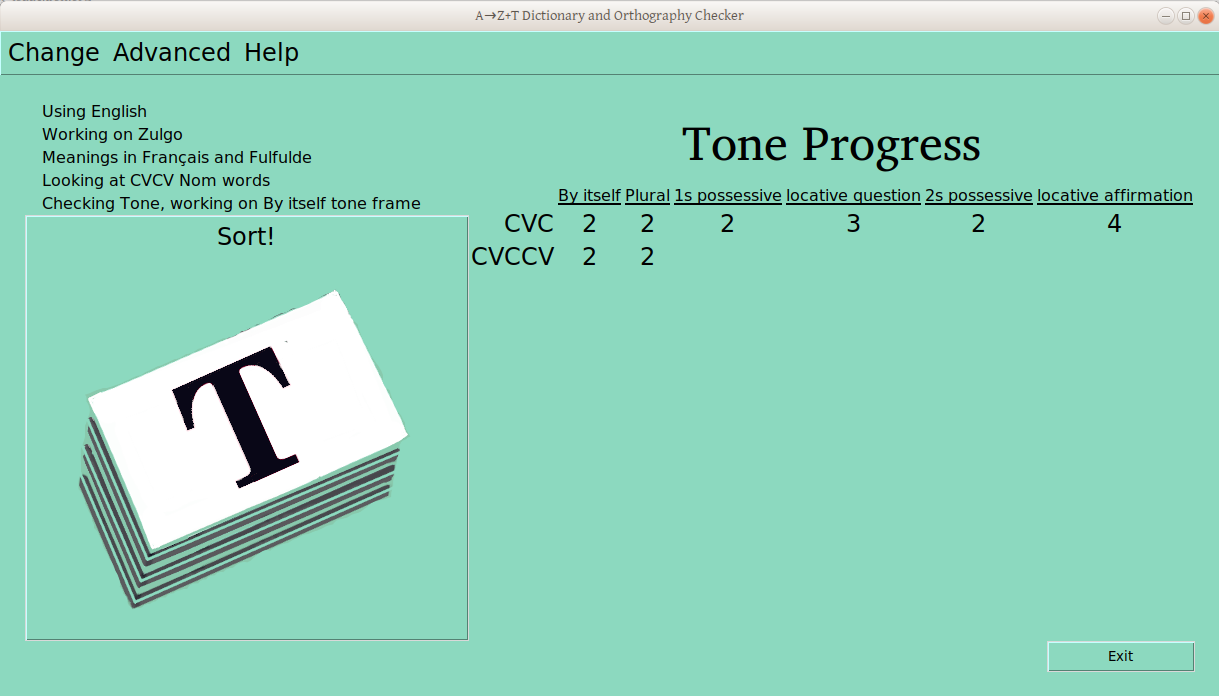
Menus
This window has a number of menus, which are intentionally hidden a bit, as the user shouldn’t have to use them much/at all. One can change which language is used for the program (Currently English and French, other translations welcome!), which is being analyzed, and one or two gloss languages (these last options depend on what is actually in the database):
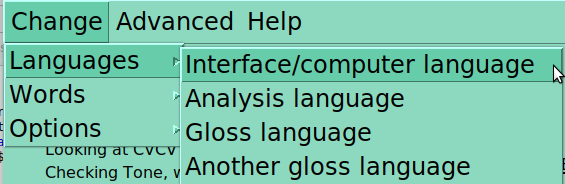
One can also change the words being looked at in a given moment. The primary search parameters are part of speech (indicated in the dictionary database) and syllable profile (analyzed by this program).
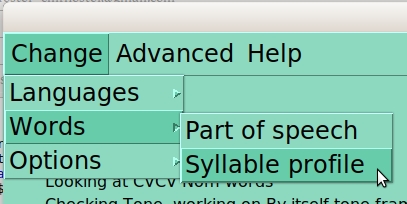
Once the group of words to be studied is selected (based on part of speech and syllable profile), The third section of the basic menu lists options relevant to that group:
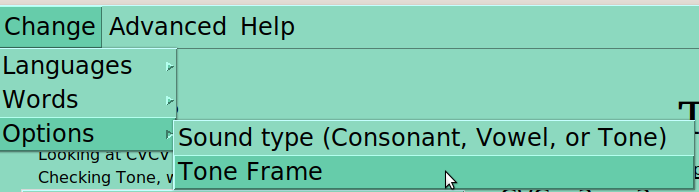
Many of these options are only meaningful when another is selected. For instance, “sound type” must be selected for ‘Tone’, before you can select which tone frame you want to use. Similarly, if you are looking at CVC nouns, you won’t see V2 or V1=V2 as options!
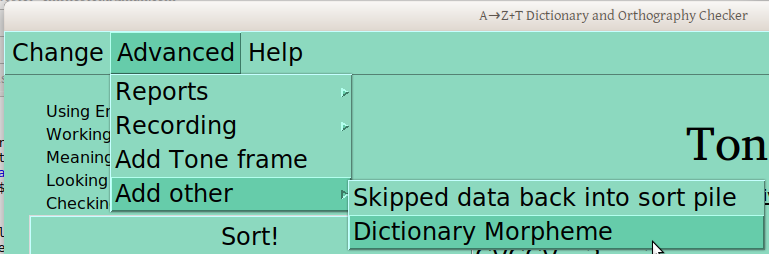
The basic function of presenting and recording card sorting judgements can be done on the basis of this first menu alone. But other functions require a bit more work, either running reports or changing something most people shouldn’t. So in the Advanced menu, you can ask for a tone report (more on that later), or a basic report of CVs (not really doing much right now).

You can also record, with one window to let you test your system, another pulls automatically from draft underlying tone groups (more later!), and the third allows you to specify words by dictionary ID in a separate file, if you want to record a specific set of words that aren’t otherwise being picked up:

This Advanced menu also gives you access to the window where you can define a new tone frame. And another lets you add stuff, like a word you find wasn’t in your database but should be, or a group of words you skipped (more on that later).
Status indicators
As you make whatever changes you like through these menus and the windows the provide, the current status is reflected in the screen, as below:
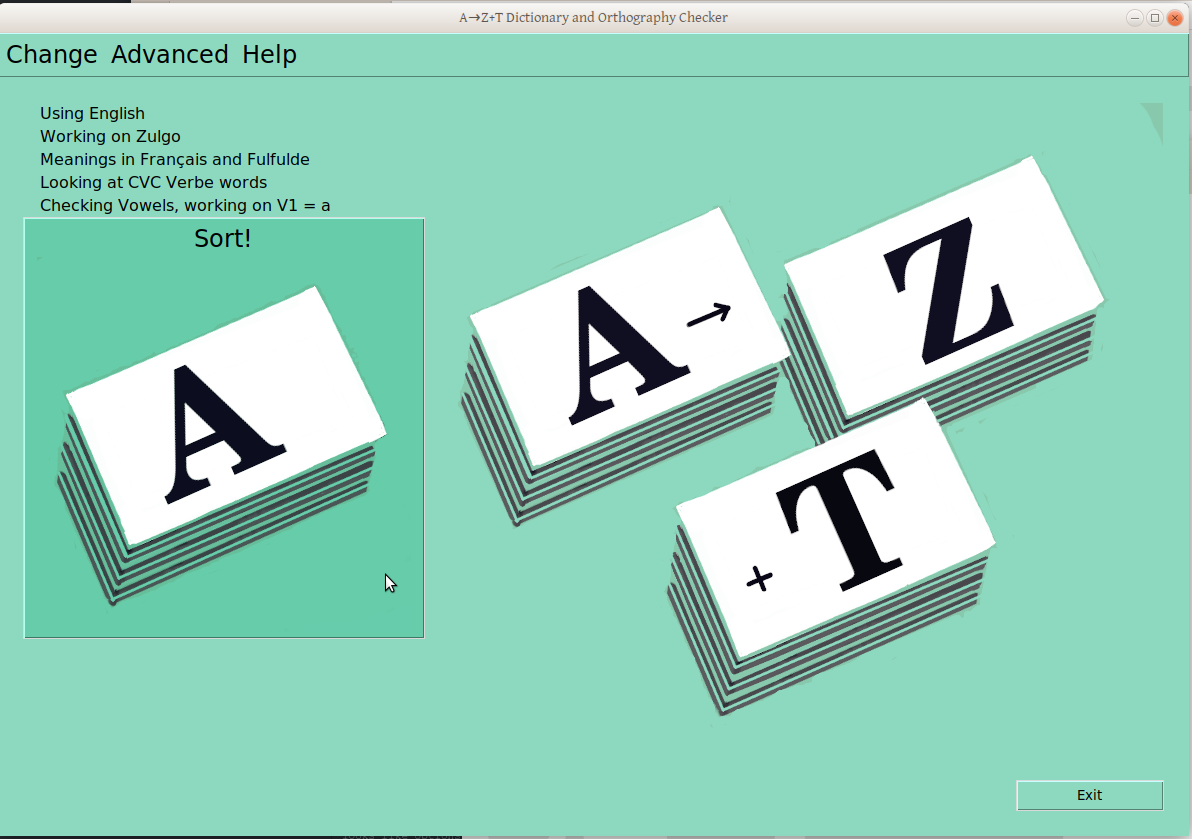
This is now looking at CVC Verbs (not CVCV Nouns, as above, and we’re now looking at the infinitive frame (not the nominal “By Itself” frame).
If your preference is for Vowels (no accounting for taste; it happens), you’ll also get an “A” card on the big “Sort!” button, just to be clear we’re working on Vowels now:
But the Vowel sorting is not so advanced as the tone one at this point; it mainly lets you look at lists of data under different filters:

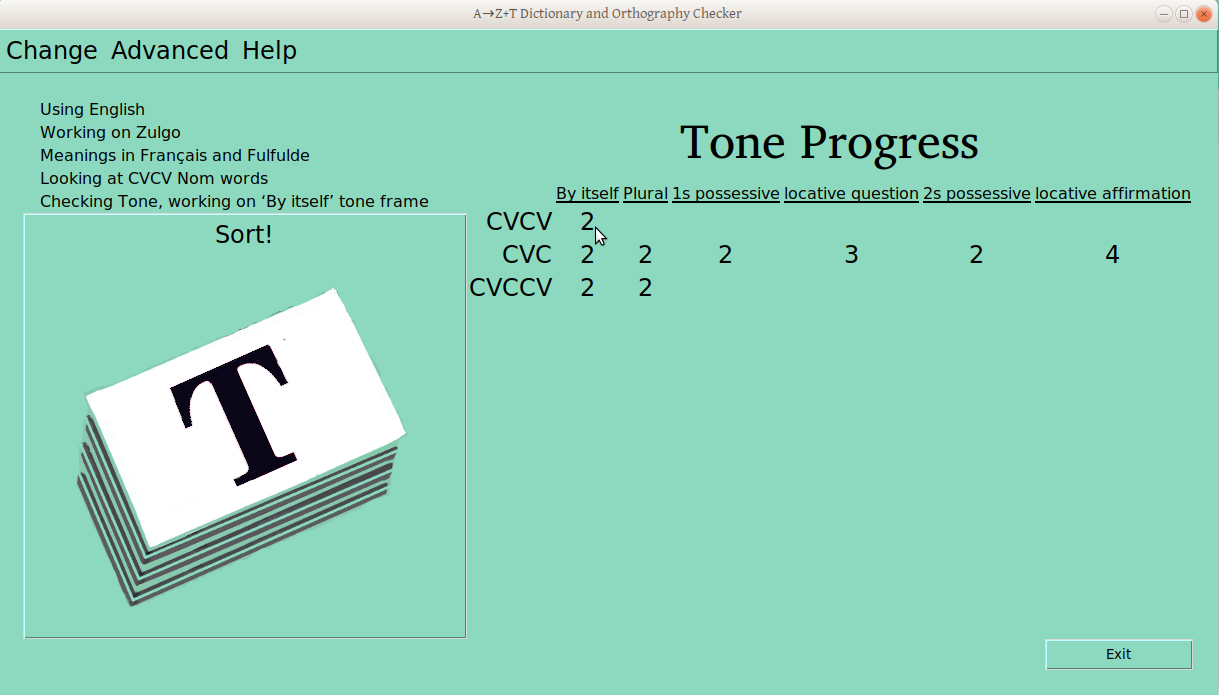
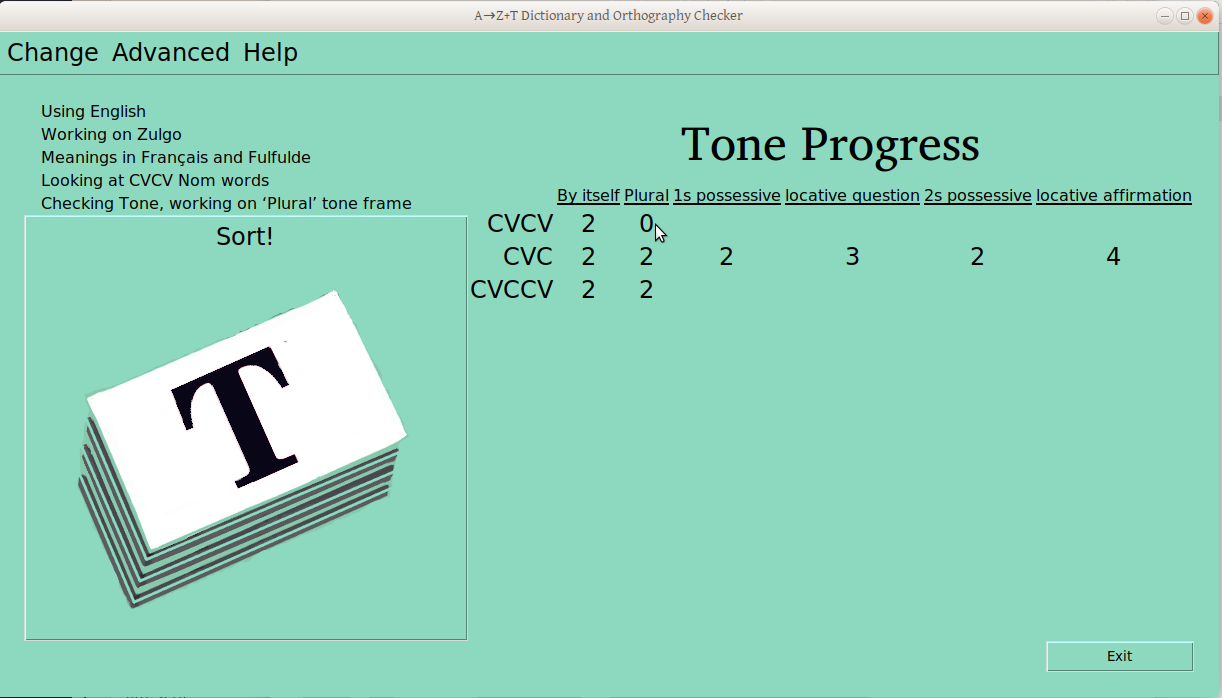
Once the verification process has started for a ps-profile combination (e.g., CVCV Nouns), the number of verified groups is displayed in the progress table:
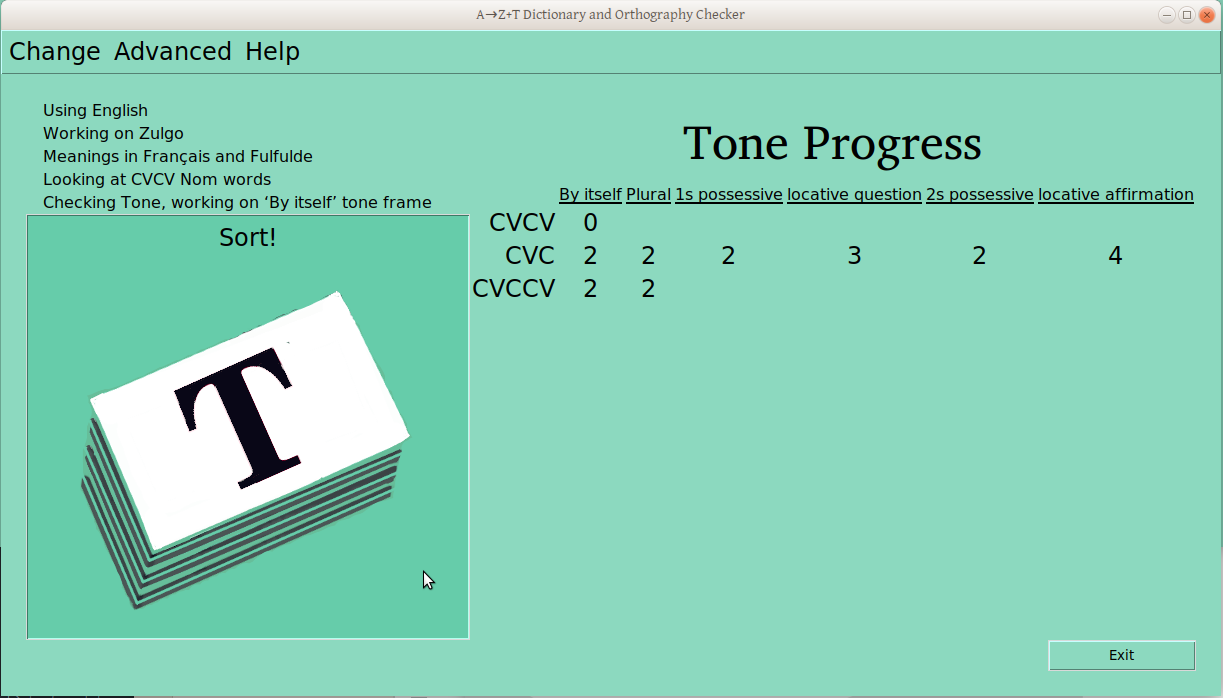
Sorting Data
When the user clicks “Sort!”, the appropriate searching and filtering is done, to provide the following screen to sort those words, one at a time:
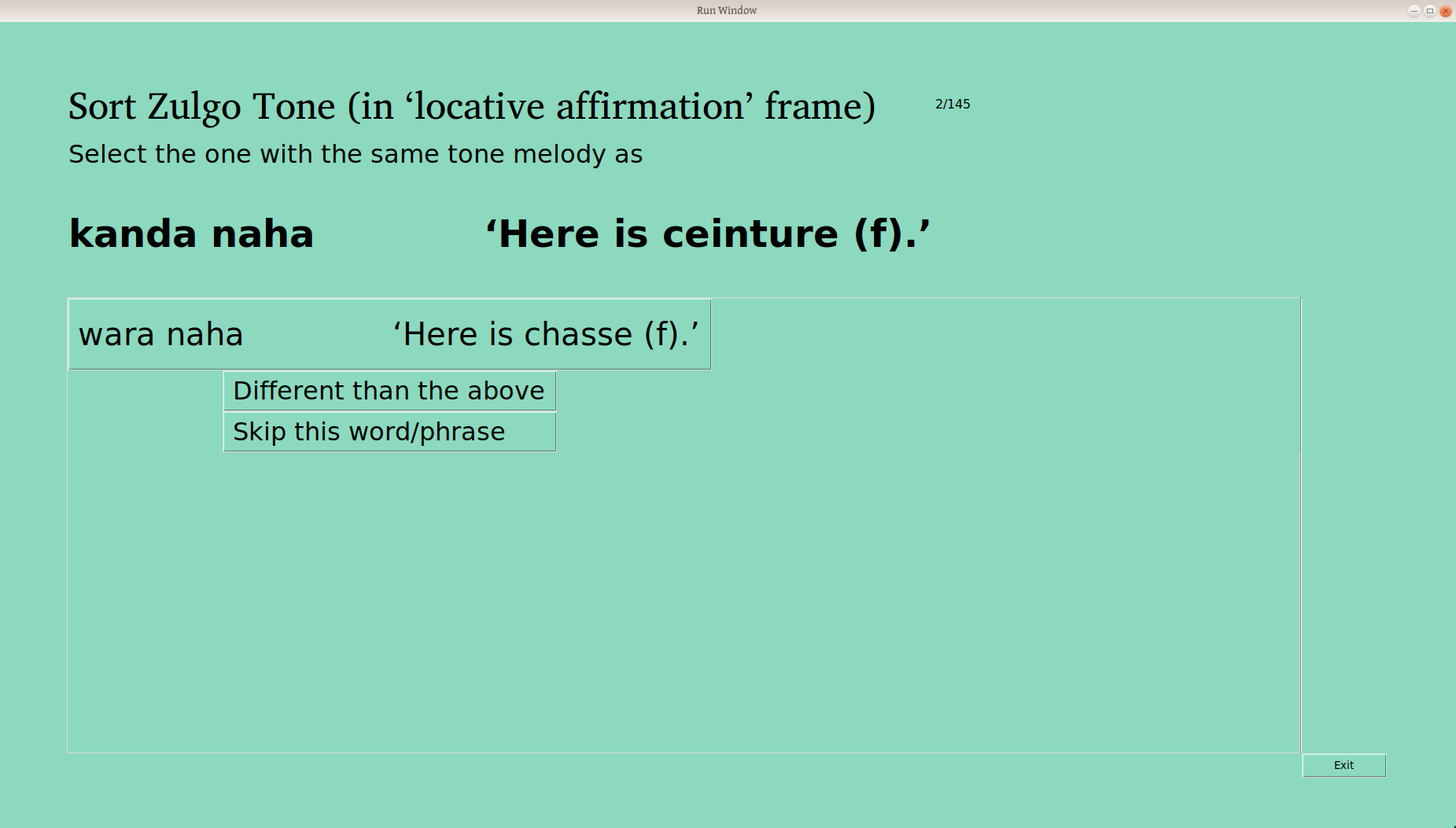
The first framed word (here wara naha, “Here is chasse” —yes, a bad combo of an English glossed frame and a French glossed word, but you wouldn’t do that, would you?) is sorted automatically into the first group, and the user is asked if the second word is the same.
The user is also given the option “Different than the above”, as well as “Skip” —there are some word/frame combinations that just don’t work, either because of the meaning, or the syntax, or particular taboos, or whatever. Excluding one word (or a couple) isn’t the end of the world, as we’re looking to understand the system here. Words that are skipped can always be sorted again later.
If the user selects “Different than the above”, that word becomes another button to select a second group, for the third word:

If that word is also different, the program gives a third group from which to select when sorting the fourth word:

Up to as many as are needed:

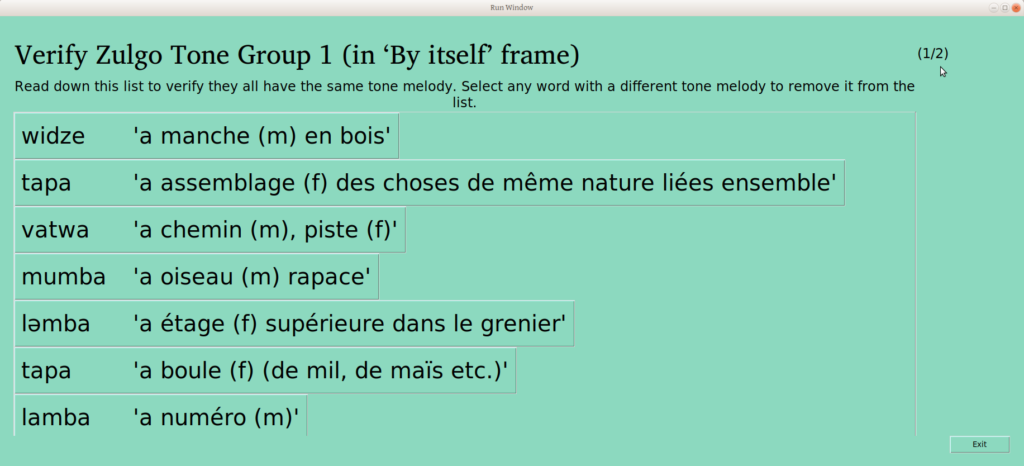
Once all the words have been sorted into groups, each group is verified, to make sure that it contains just one tone melody. Once the user verifies a group, the main window updates:
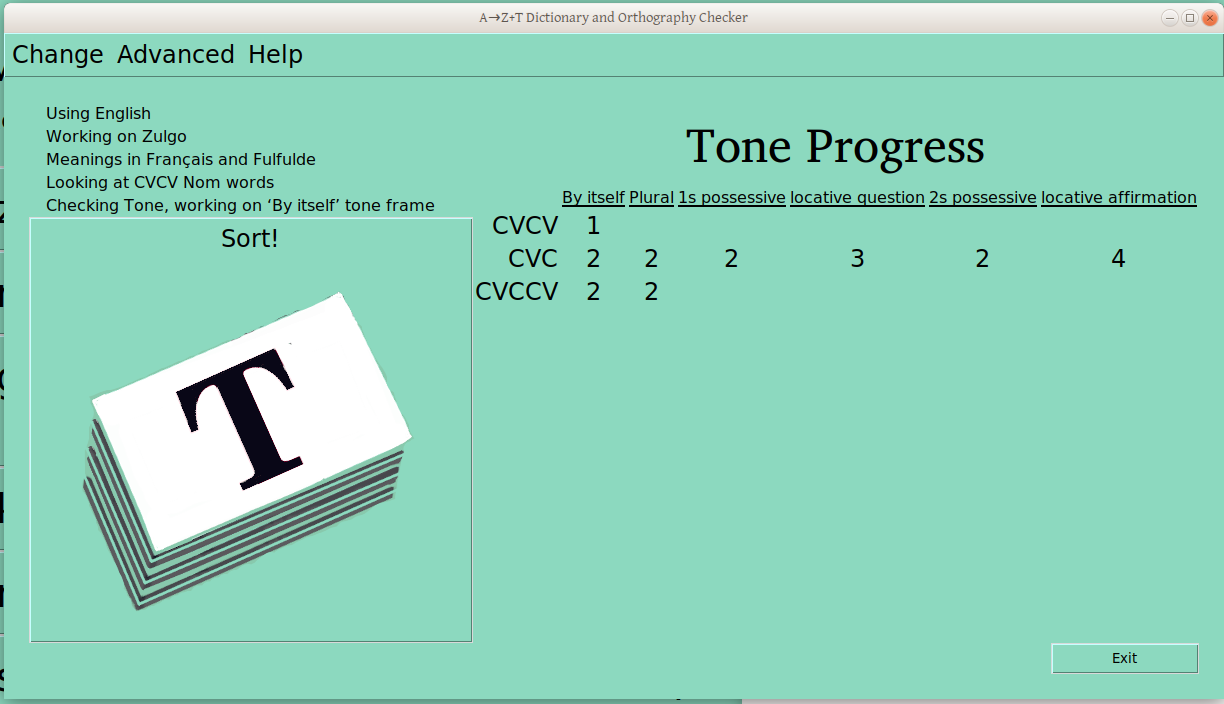
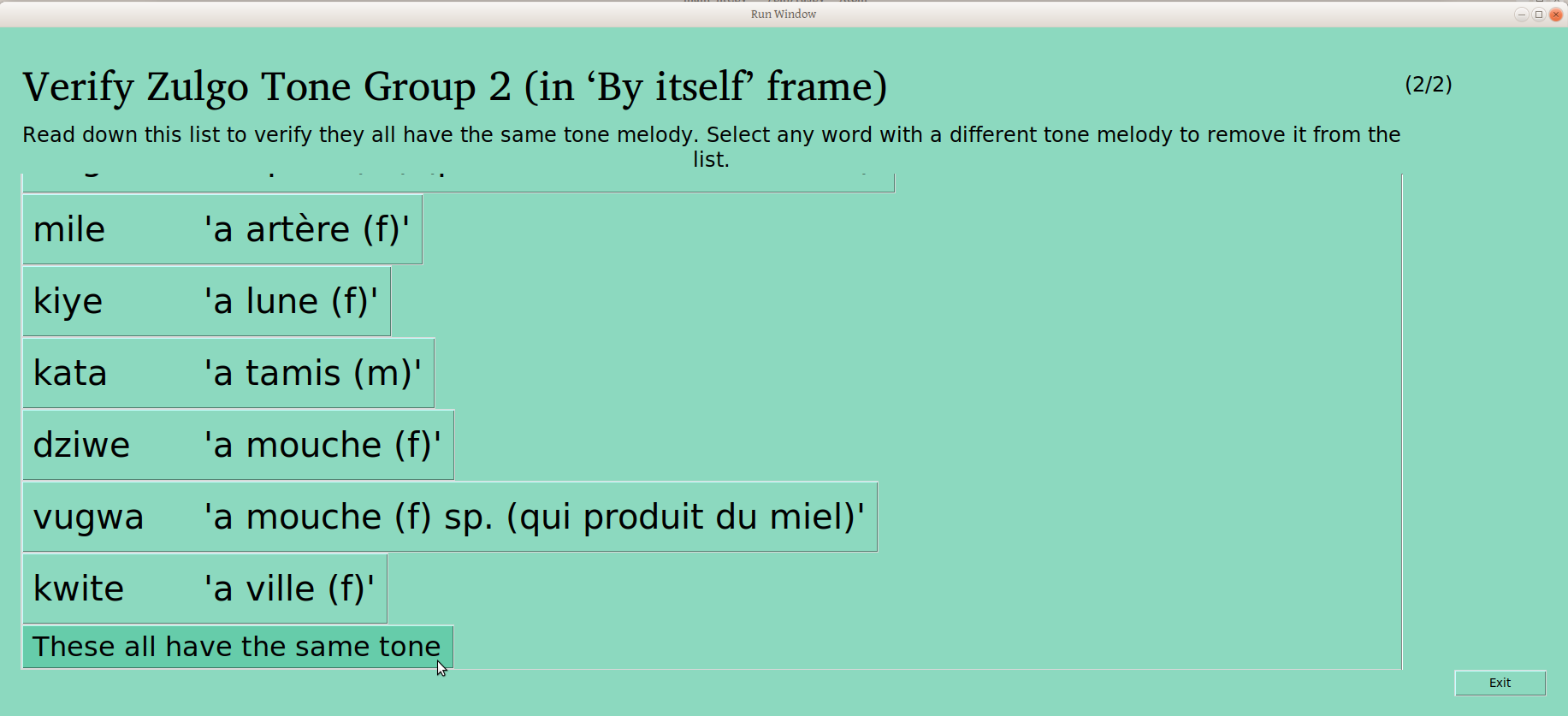
Once the piles are sorted and confirmed to be different, the user is presented with a list of words like this:
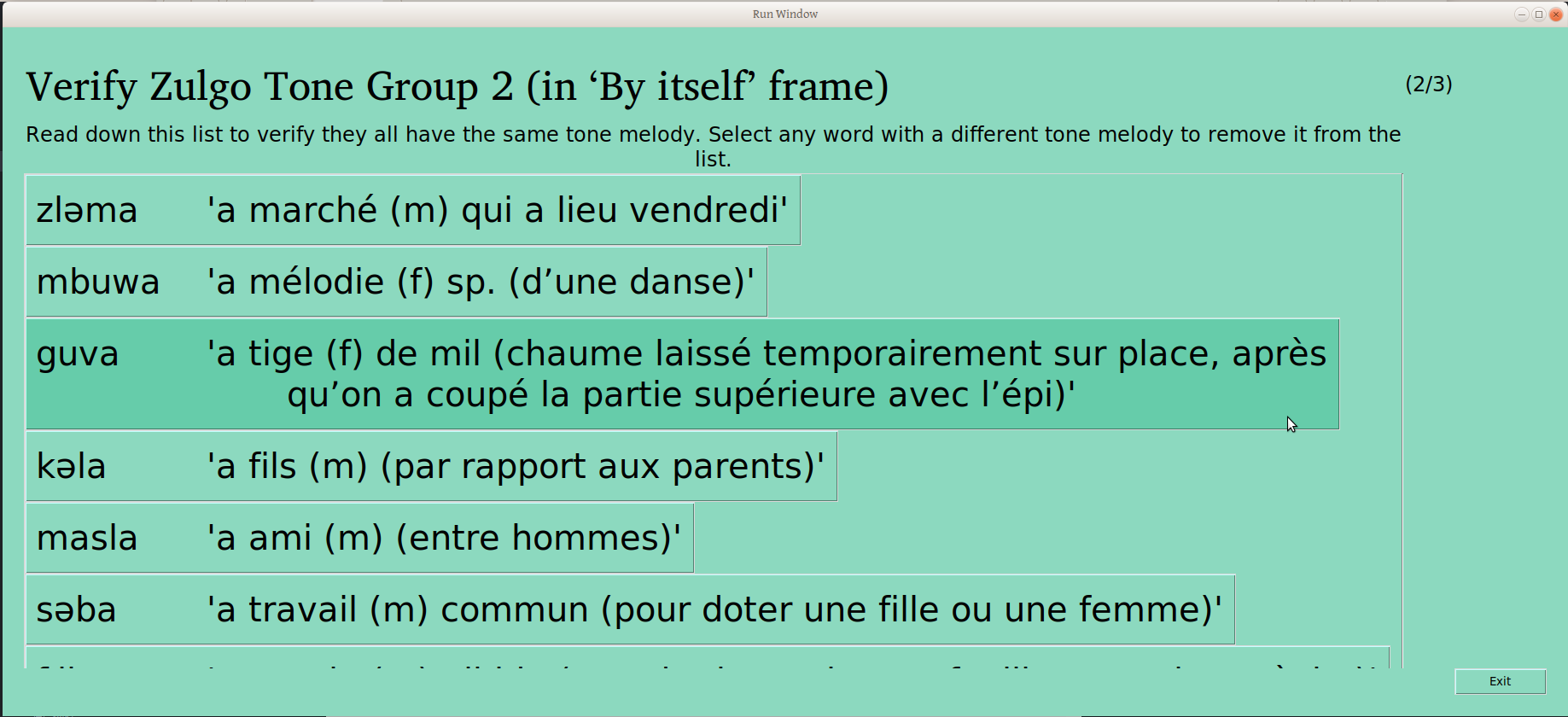
The user can scroll through the whole list, clicking on any words that don’t belong to remove them. The button on the bottom of the page gives the user the opportunity to confirm that the remaining words are the same (People who care about this kind of detail may note that progress is indicated in the upper right –this is the second of three groups being verified):
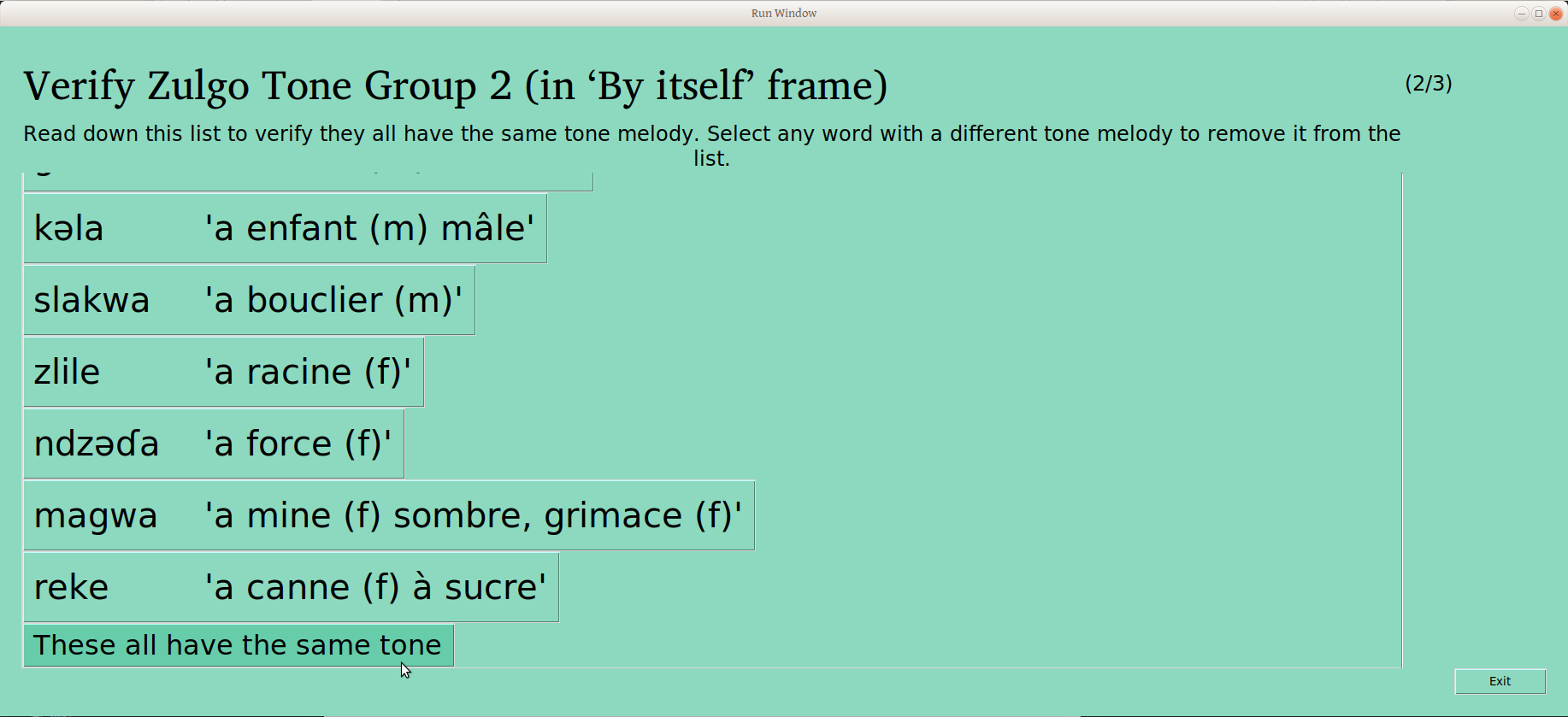
Once that last button is clicked, the group is considered verified, and this is reflected on the status page:
And so on for a third and more groups, for as many as the user sorted the data into:

But as anyone who has run a participatory workshop can tell you, these processes are not particularly linear. Rather, there is often the need to circle back and repeat a process. So for instance, the fact that these three groups are each just one tone pattern does not mean that they are each different from each other. So we present the user this screen:

This allows the user to confirm that “these are all different”, or to say that two or more should be joined (something we would expect if there were lots of groups!). If the user selects one of the groups, the following window is presented; the first selected group is now presented as a given, and the user is asked which other group is the same.
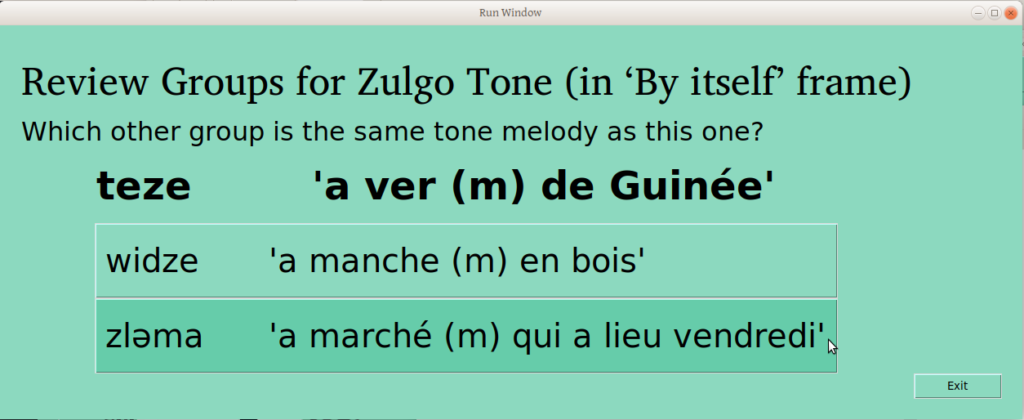
Note that all of these windows have “Exit” buttons, in case the user arrives on a page by accident. Most changes are written to file as soon as a process is finished (e.g., joining groups), so this whole process should be fairly amenable to a non-linear and interrupted work flow.
If groups are joined (as above), the user is again presented the choice to join any of the remaining groups. If you made one too many groups, who is to say there isn’t another one (or two!) excessive divisions in your groupings

Back to the cyclical nature of this process, if groups are joined, that means the joined group is no longer verified! So we verify it again (this time as one of two groups).
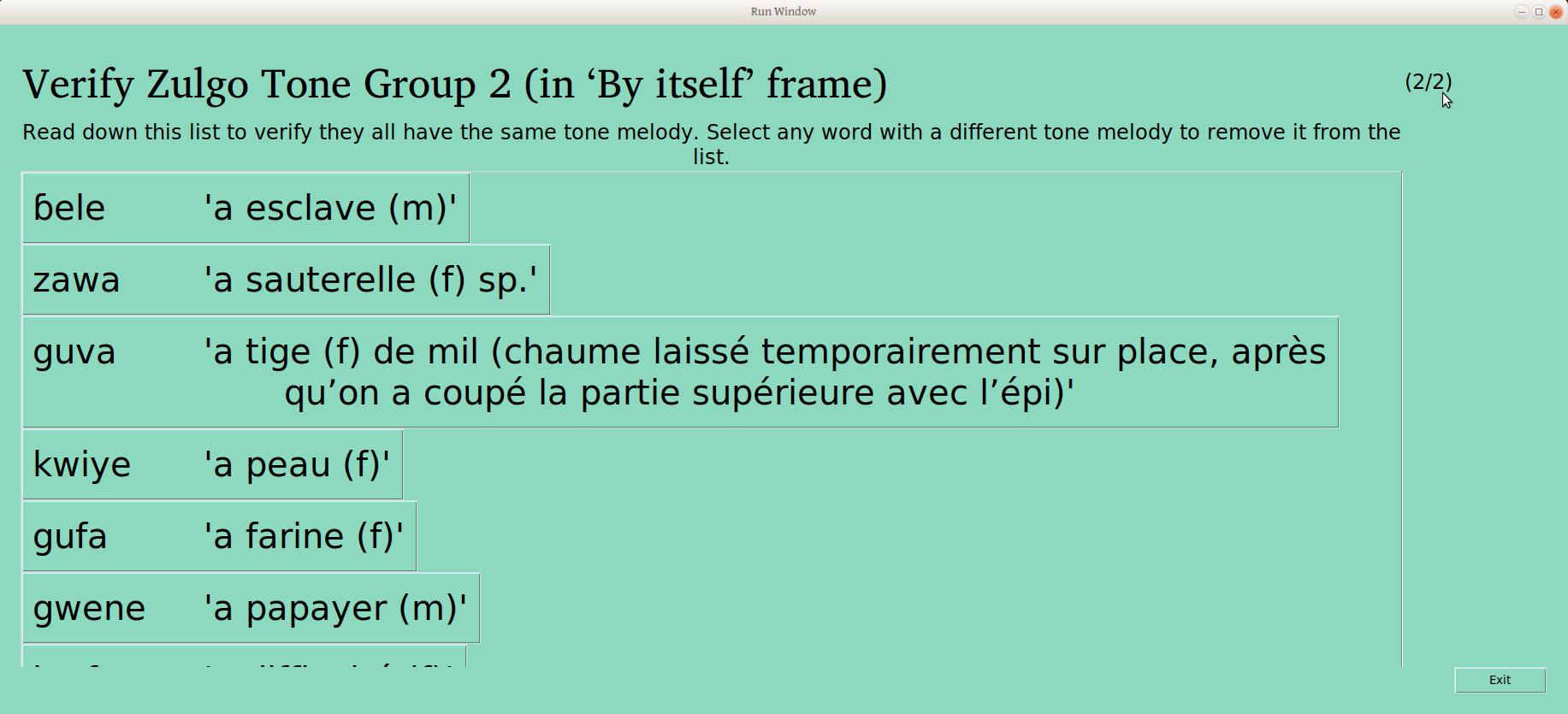
The user is again offered the chance to remove from this group any words or phrases (depending on the frame) which do not belong (anyone want to sing the Sesame Street song?). Any words that are removed from this group in this process are then sorted again:

In the sorting process, if any words are added to the group, it is marked as unverified, and sent to the user to verify again:
If the cards that were pulled earlier are resorted into multiple groups, each is verified again:
So just like in a physical card sorting workshop, word/phrase groupings are sorted, verified, and joined until everyone is happy that each pile is just one thing, and no two piles are the same.
Only in this case, the computer is tracking all of this, so when you’re done, you’re done —no writing down on each card which group it was in, then forgetting to commit that to your database months later.
And this progress is visible in the main window:
The Tone Report
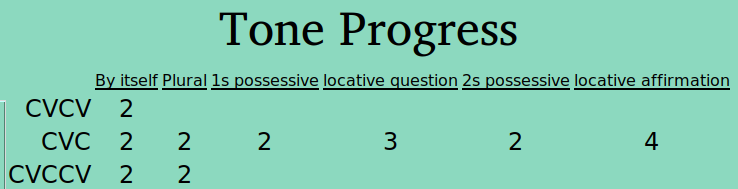
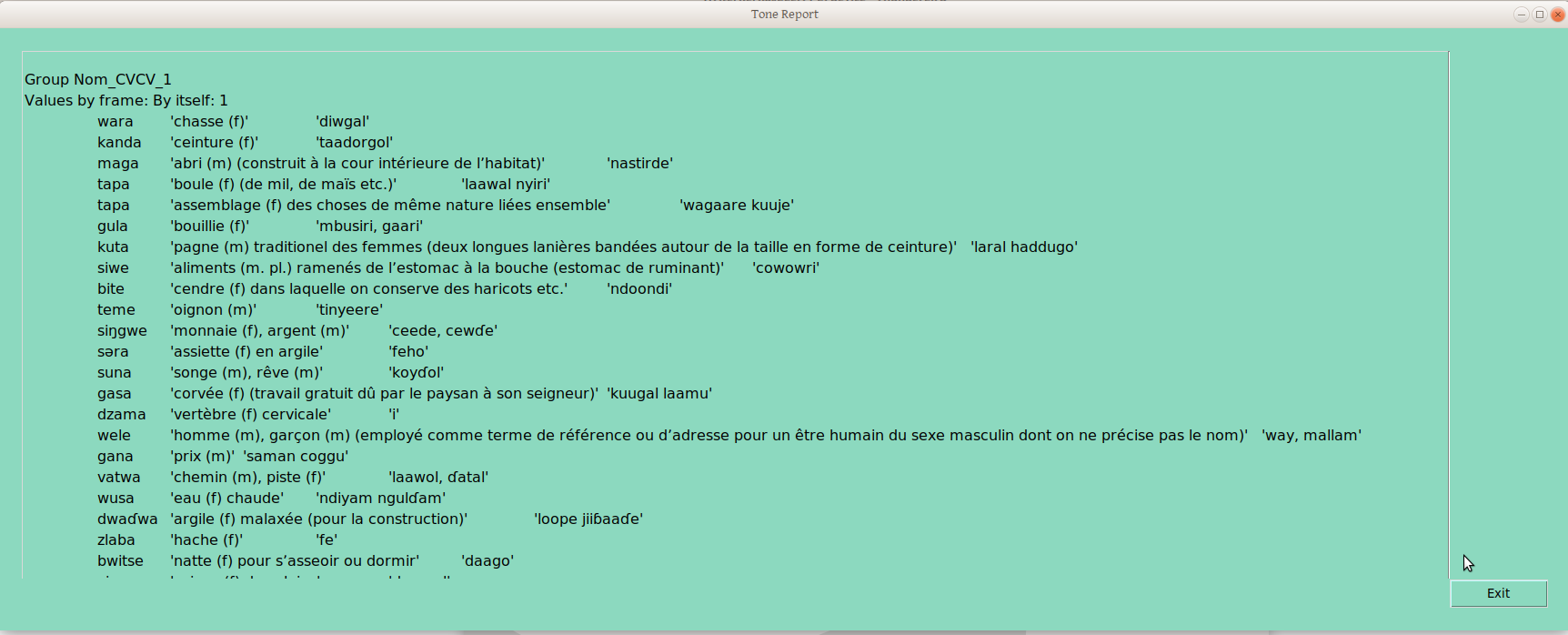
Now, the above is exciting enough for me, given the number of times I’ve run into people that seem to feel that sorting by part of speech and syllable profile, then rigorously controlling and documenting surface forms, is just too much work. But it doesn’t stop there; many of us want to do something with this data, like make a report. So the Tone report option produces a report which groups words (within the ps-profile we’re studying at the moment!) according to their groupings in each tone frame:
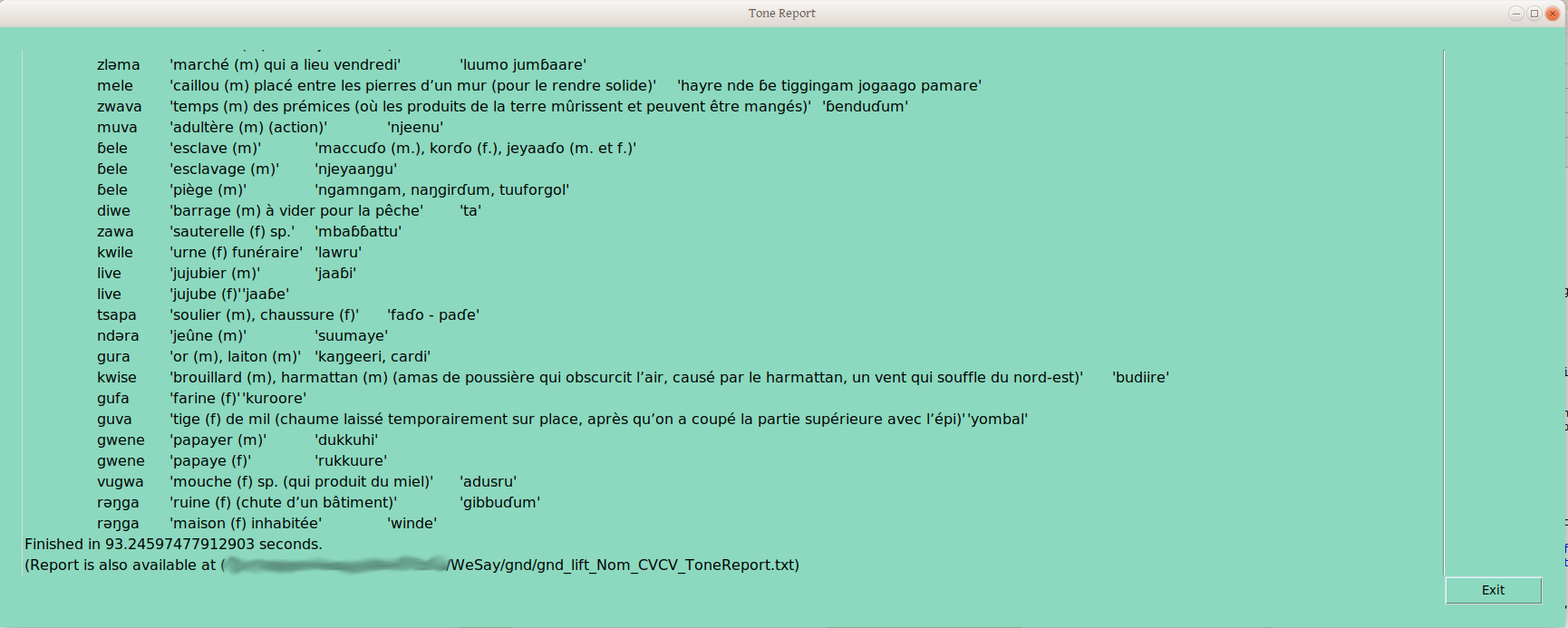
This is the same thing human linguists do, just on a computer — so it is done faster, and the resulting draft underlying forms are put into the database in that time. But perhaps you’re thinking you could find and sort 145 CVCV Nouns into tone groups based on a single frame, and mark which was which in FLEx, in under 100 seconds, too. And I admit that sorting by one frame just isn’t that impressive —and not what we tonologists do. We sort by how words split up across a number of frames, until new frames no longer produce new groups. So we look at another tone frame (recall the window where you can define these yourself?):
When you verify a group in that frame:

Then in another:

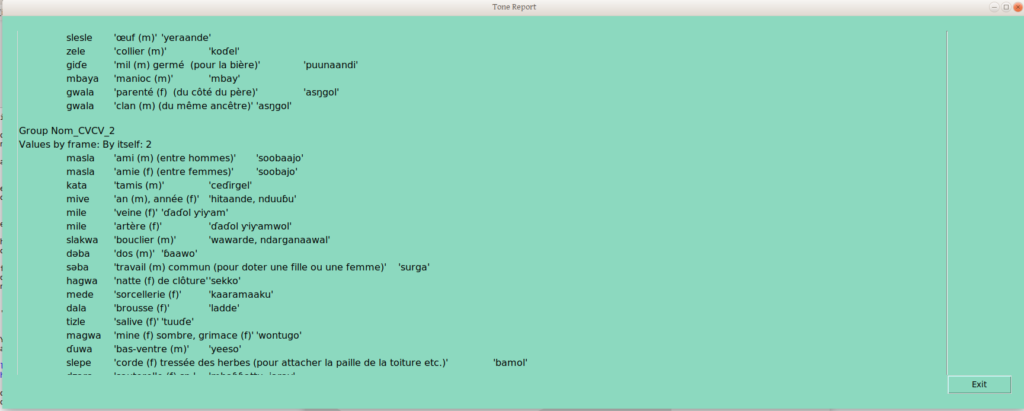
Once that second frame has a couple groups verified, the tone report becomes a little more interesting:
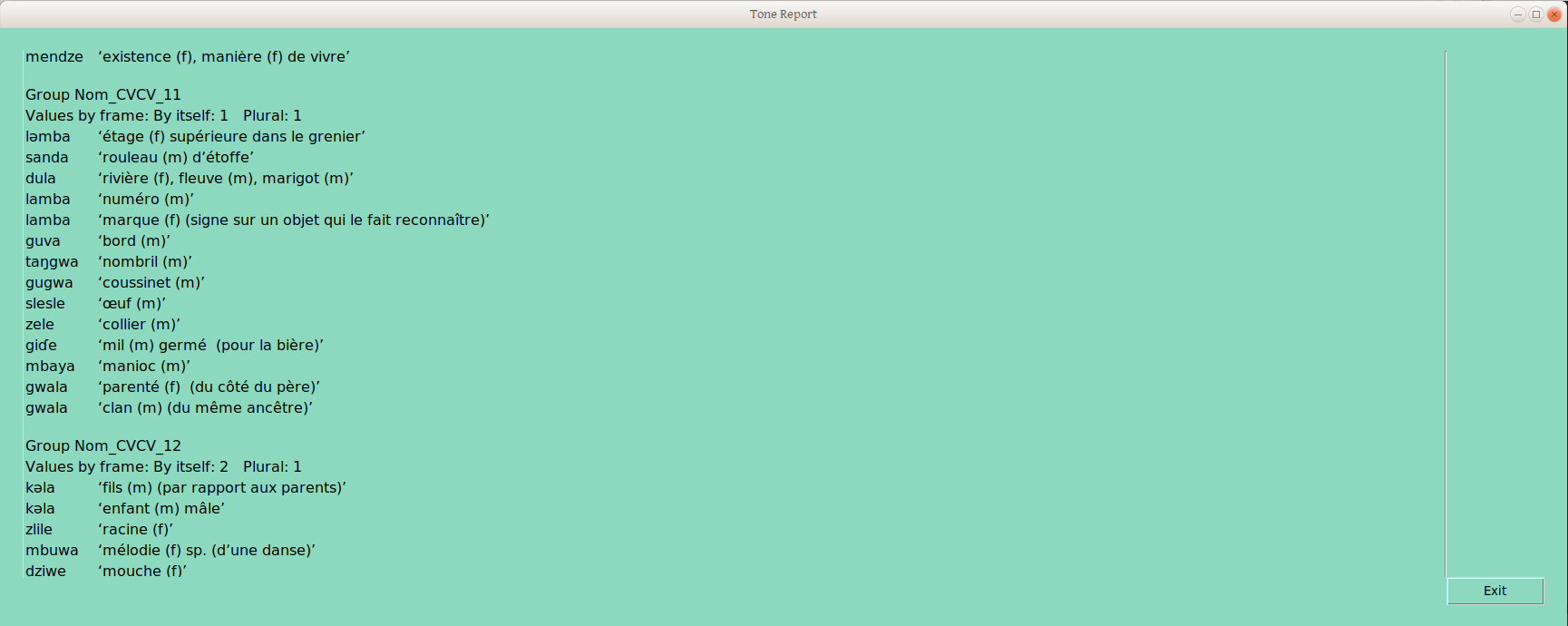
The group provisionally labelled “Nom_CVCV_11” (yes, there are too many groups, as a result of my highly random decisions on group placements) is defined by the combination of group 1 in the “By Itself” frame, and group 1 in the “Plural” frame.
Group Nom_CVCV_12 differs in the “By Itself” grouping, though not in the “Plural” grouping —in this way we handle neutralizing contexts: any word grouping that is distinguished from another group in any frame gets its own (draft underlying tone) group.
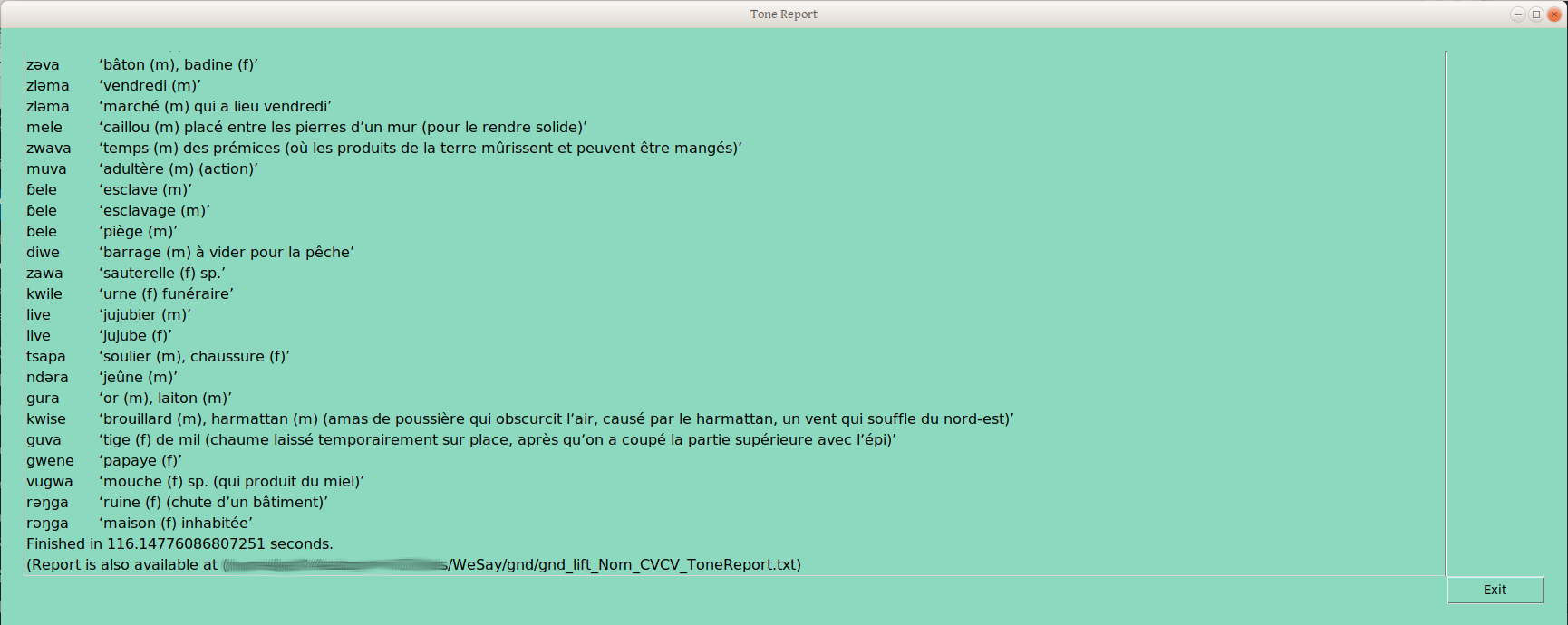
Yes, there are of course groupings which don’t indicate underlying forms, such as if one group differed from another by the presence and absence of depressor consonants.
But still, I’m impressed that we can sort 145 CVCV nouns by two different frame groupings, in less than 120 seconds (32 CVC Nouns sort across six tone frames in about 45 seconds). These groupings (e.g., Nom_CVCV_12) are immediately written to LIFT, so could be available in FLEx, to sort on. Because this report costs almost no time (unlike physically sorting cards), this report can be done after each of a number of different sortings, and the progression of group splits can be monitored in more or less real time.
One caveat I would mention. Assuming the words are found in more or less the same order, their names should be more or less stable, unless a new frame creates a real split. But there is no reason that it should be so —neither I nor A→Z+T make any claim that these groupings are anything more than draft underlying form groupings, including the shape of those underlying forms. That is, words marked Nom_CVCV_12 may ultimately be called H, Low, mid, or something else — that is for the analyst to figure out (Yay! more time analyzing, less time collecting, organizing, and archiving data!).
One perhaps less obvious extension of this caveat is that Nom_CVCV_1 has no implicit relationship with Nom_CVC_1, apart from that each was grouped first when their syllable profile was analyzed. So the linguist still needs to figure out which CV draft underlying tone melody groupings correspond to which CVC, CVCV, etc draft underlying tone melody grouping —but why would we wan to cut out the most fun part?
Recording
For many people, participatory card sorting is just uninteresting work —either because they question its scientific value, or because of its notoriety for data to not survive the workshop. How many times have you finished a workshop with hours of recordings, wondering when you would have the time to cut, label, organize and archive them? But what if you could make recordings in a way that immediately cropped, tagged, and made them available in your lexical database?
This tool provides a function which goes through the most recent tone report groupings (we’ll be doing that often, right?), and pulls (currently five) examples from each, and presents them one at a time on a page like this:
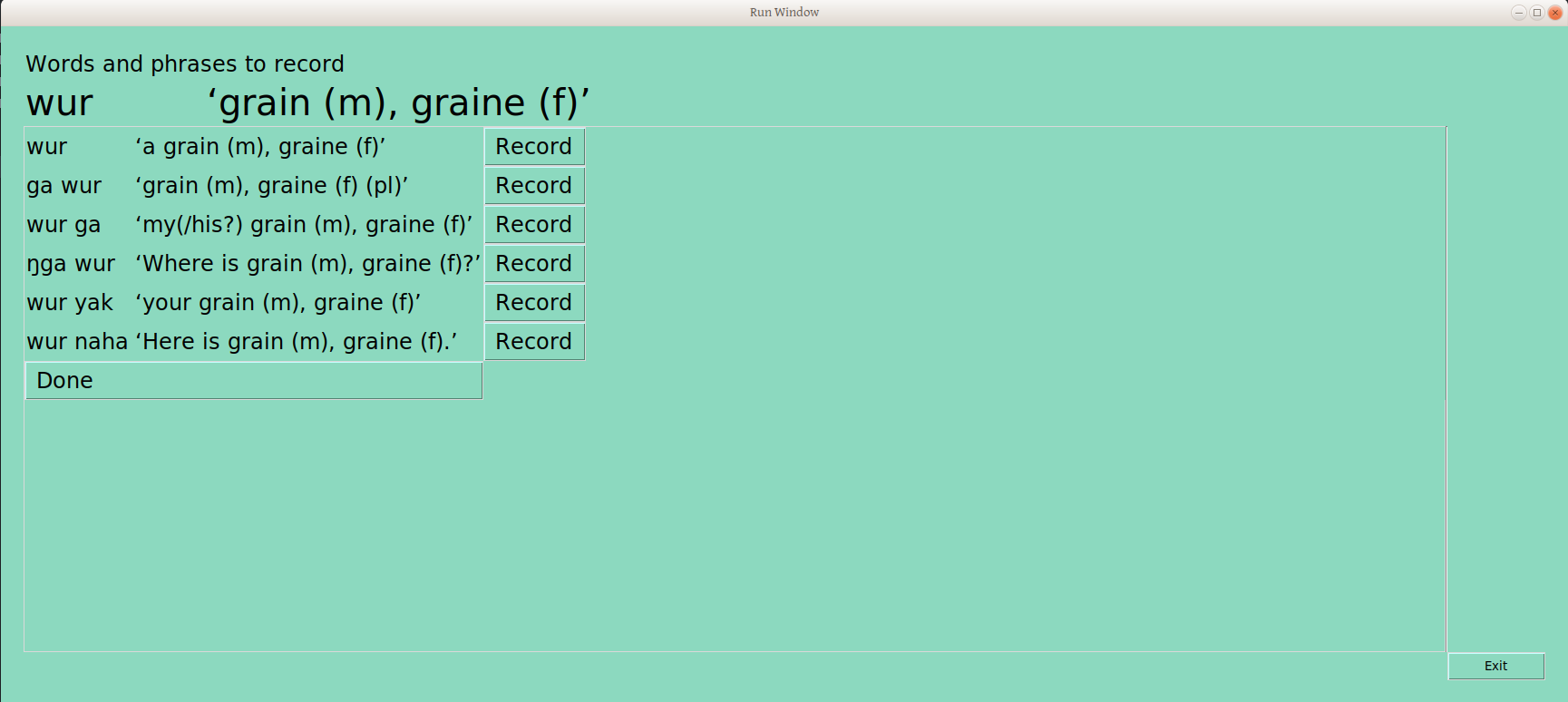
Below the bold title with word form and gloss are six rows with that word in each of the frames where it has been sorted: the word form is framed, as well as the gloss, so the user can see the entire context of what has been sorted (this info is taken from the LIFT file, where we put it earlier for safekeeping). Next to each line is a record button. The user presses down on the button, talks, and lifts up on the button, resulting in a sound file recording, storing in the repository’s “audio” folder, and a line in the LIFT example field telling us what that file is named (which is something like Nom_CVC_75438977-7cd0-49ac-8cae-ffb88cc606a1_ga_wur_grain_(m),graine(f)(pl).wav, for those interested). And the user now has a play button, to hear back what was recorded, and a redo button, in case it should be done again (chickens, anyone?)
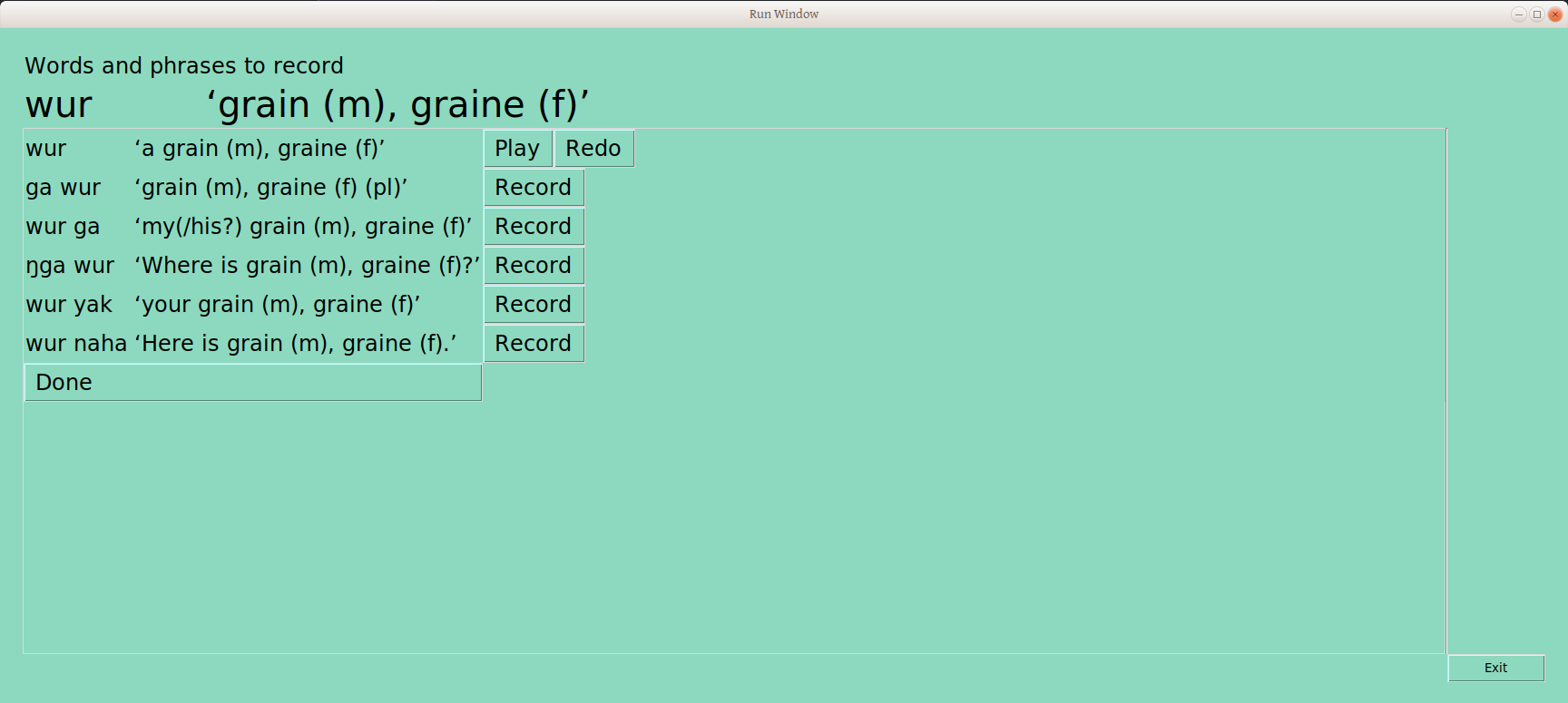
The user can go down the page, until all are done:
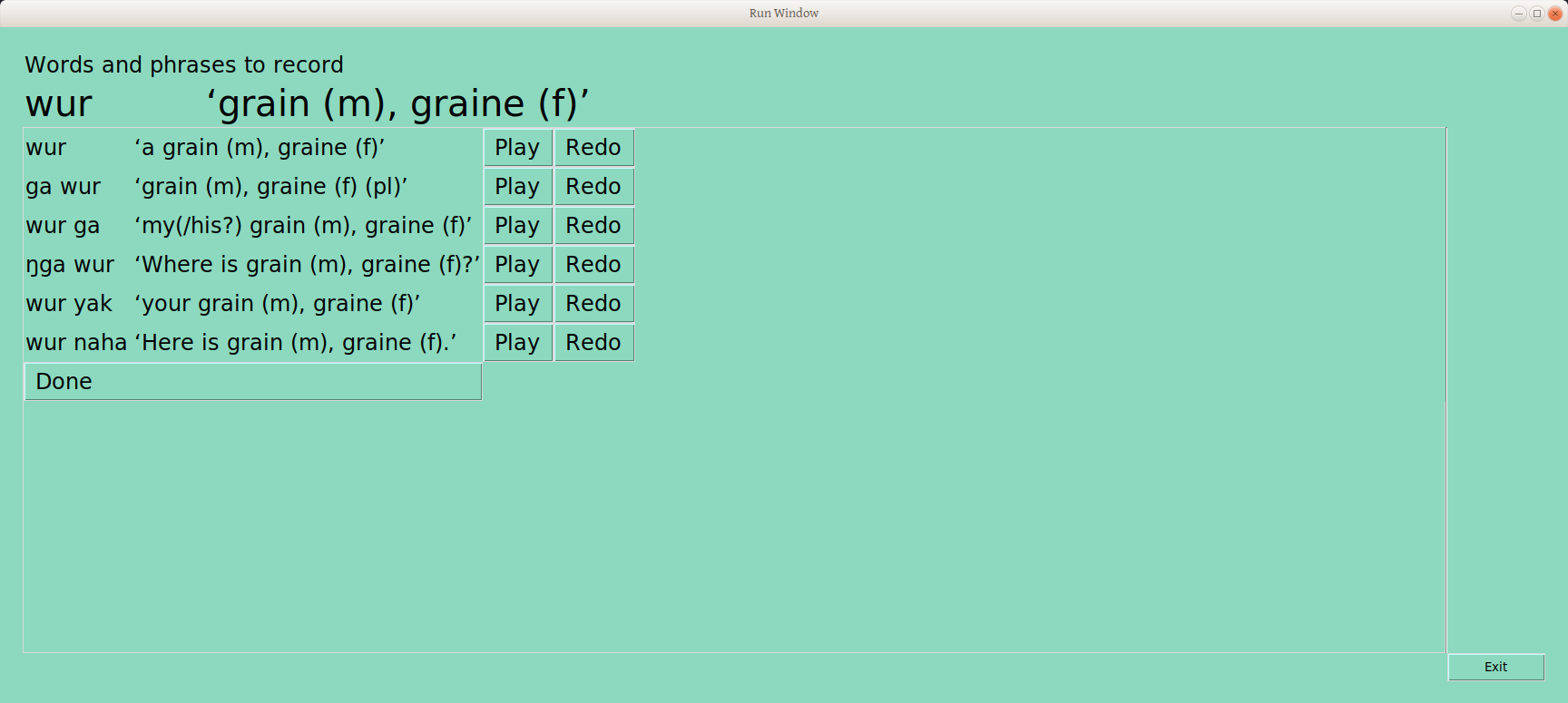
Once the user selects “Done,” an example word from the next grouping is presented. Once each group has one word, the user is given a second word from each group. This was designed to allow even a minimal amount of recording to most likely include each of the draft underlying tone groups.
Conclusion
This has been a brief overview of the user interface of A→Z+T, the dictionary and orthography checker. I have not discussed the inner workings of the tool, apart from the logic relative to the user, but may do that at a later date.
Please let me know (in the comments or by Email) if there is anything about the user interface (e.g., placement, fonts/sizes, wording) that you think might hinder the user experience. I hope to finish translations into French early next week, so I hope to finalize at least this version of text for now soon.