Last month I taught the FLEx II course at CoLang, held at UTA. It was very interesting trying to teach to about 45 students, coming for a great variety of backgrounds, but I think we all learned something. There was one thing that I taught, which I thought deserved further write-up, so I’ll do that here.
The problem is not immediately obvious, unless you spend lots of time thinking about how FLEx does what it does, in particular how writing systems work. But when you want to copy data from a field that is encoded in a particular writing system, into a field that is encoded in another writing system, you can’t just bulk copy and get results you might expect. The reason is that the data itself is tagged for which writing system it is in, and not just the field. So you can, theoretically, have Spanish data in a field that is supposed to have English. But this is actually a strength, as it allows you to tag one word or sentence in its correct language, even if it is surrounded by another language, all within the same field (like if you write a note in English, but include in the note words in another language). All data is tracked by writing system, and you don’t loose that information when you copy from one field to another.
So, the task we were working on, which you may need to do some day, was copying data from one writing sytem, to use as a base for another. For instance, if you have data in a practical working orthography, and you want to also have an IPA field, you may notice (as I hope is true) that much of your orthography transfers directly over to the IPA. And for those things that don’t, there should be regular changes (like substituting [ɸ] for ‘ph’). This task is just begging to be done through bulk editing. Why type all that over again, just to change a few phonemes here and there? Why not make most of the systematic changes systematically? But we can’t just copy a practical orthography field into an IPA field, since the data would still be encoded as the practical orthography, even if the field should contain IPA data. So here’s what you should do.
First off, I assume you have your two writing systems set up; I’m using Mbo and the IPA variant in these screenshots:
Go to the Lexicon pane:
Then Select Bulk Edit Entries:
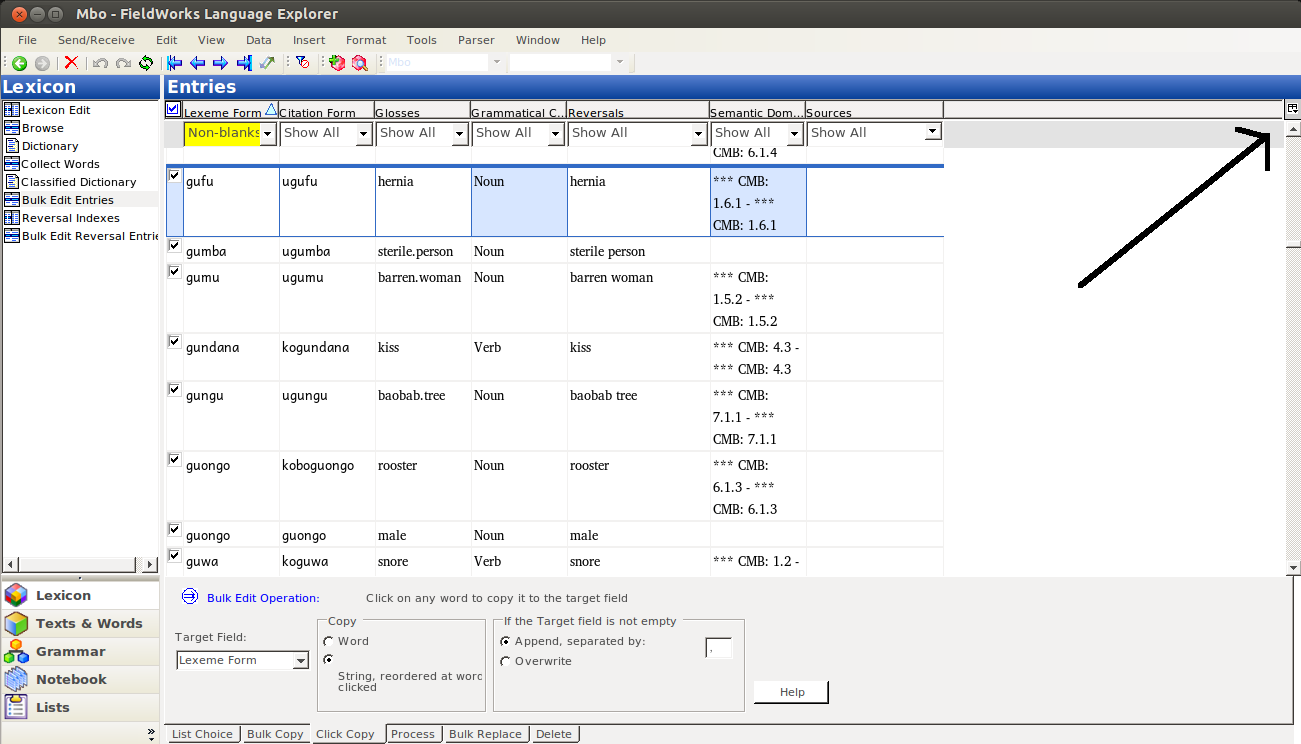
To be able to operate on both fields, you need to make them both visible. Click on the “Configure which columns to display” button:
Then click on More Column Choices (unless your IPA field is in the list, in which case you just select it):
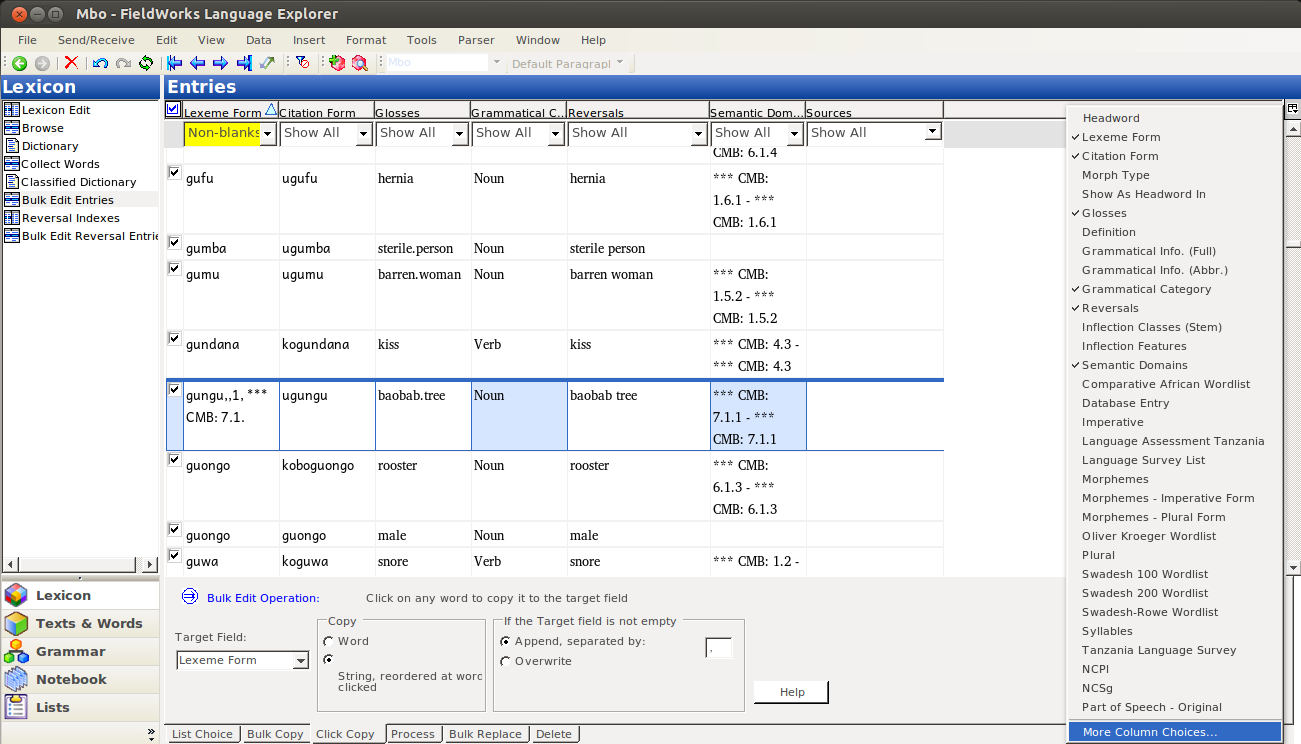
In the dialog that comes up, you selct the Lexeme form field (or whatever field you’re copying to). Yes, it is already on the right; we want to display the Lexeme form field twice, once in each of two writing systems:
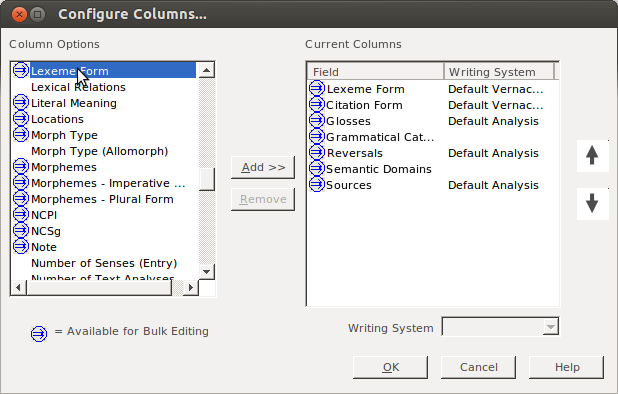
Click Add:
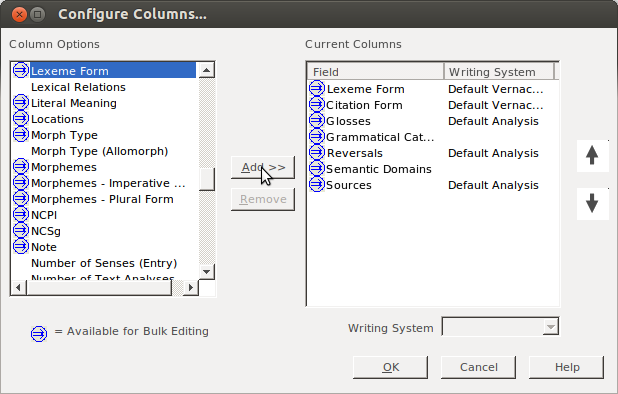
Initially you will probably have the same writing system for each of the two fields:

change one to the IPA variant:
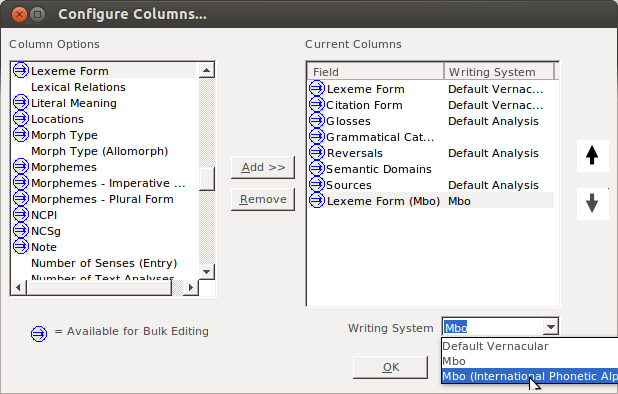
then I like to move that second field up, so it will display next to the other one. While the field is selected, click on the up arrow:
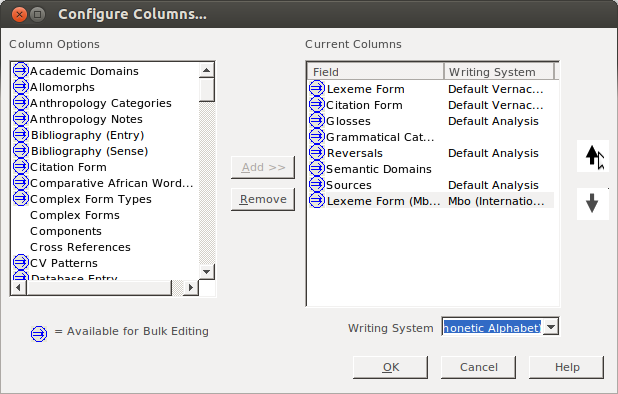
Then keep clicking until it is in place:
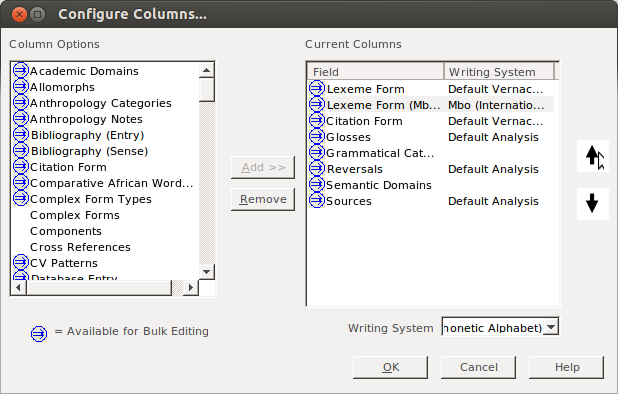
Now that you have everything situated, click on OK:

That should take you back to the bulk edit pane, where you should see your IPA field. Assuming you’re just starting to work in this field, it should be empty:
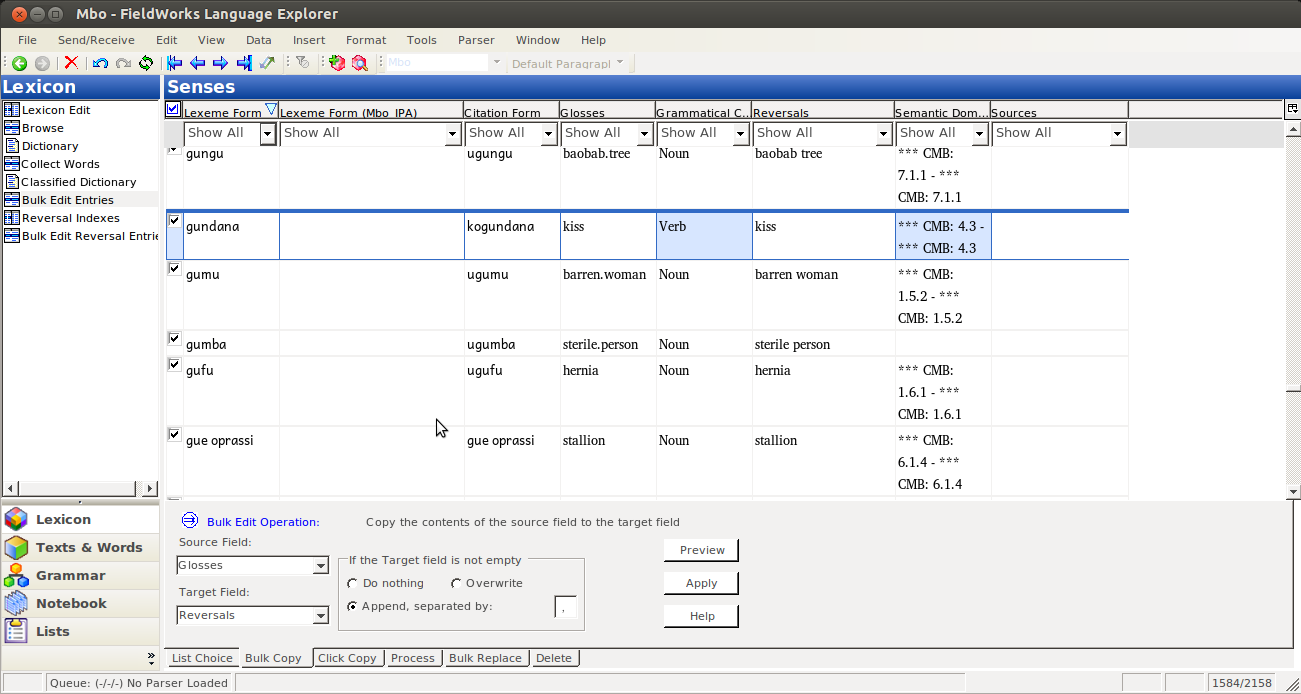
Then you Bulk edit, like normal, by selecting the Source Field (the one with data in it):
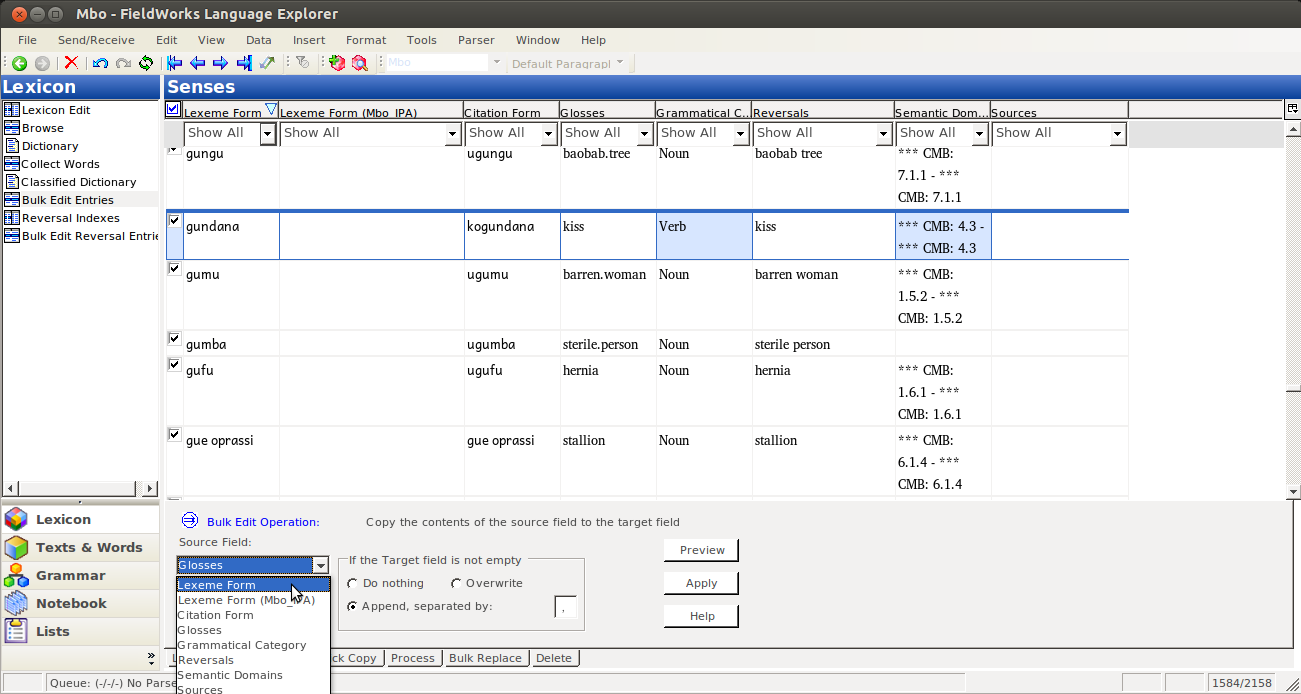
and the Target Field:
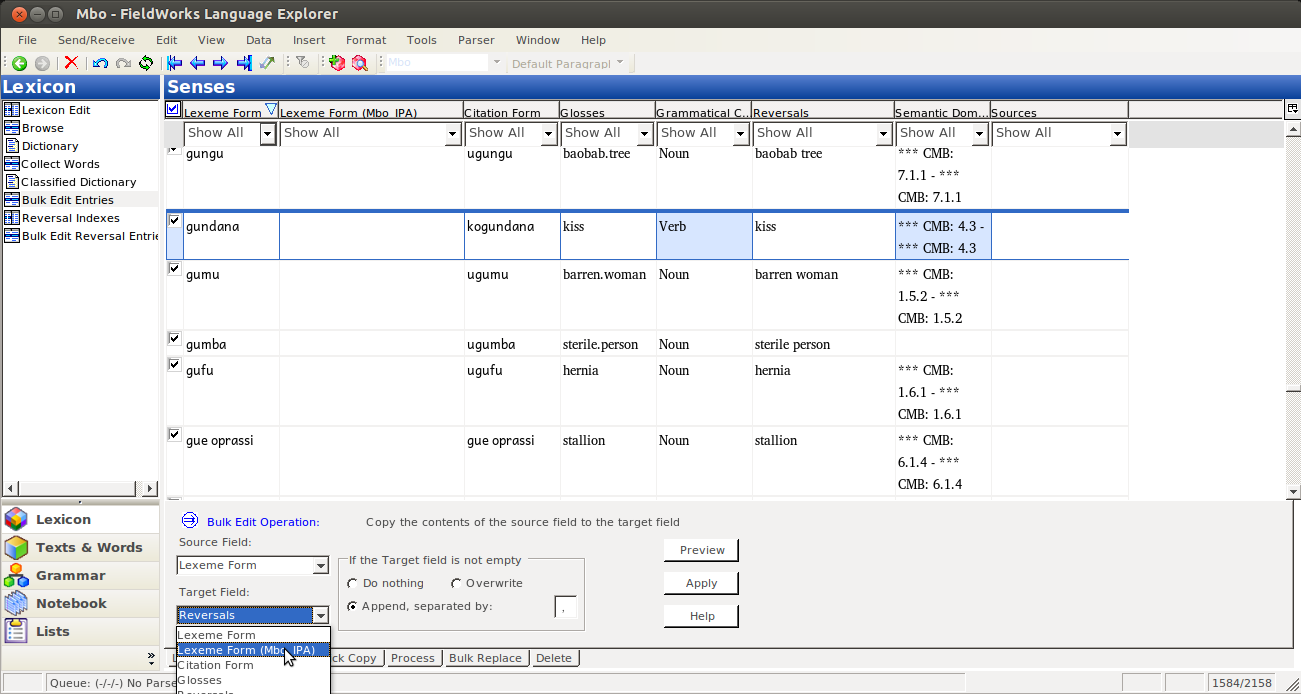
As always, you want to preview your bulk edit, to make sure it’s doing what you expect:

And you should see blue arrows going from nothing to data, which matches the field next to it:
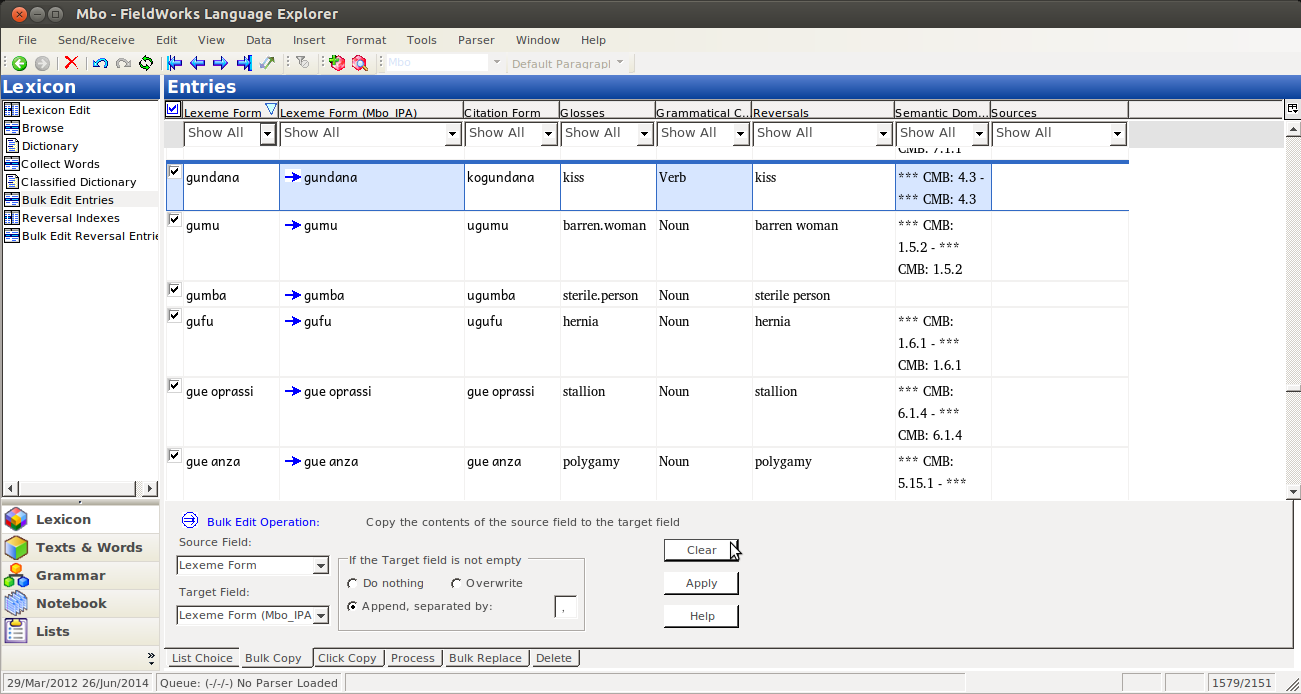
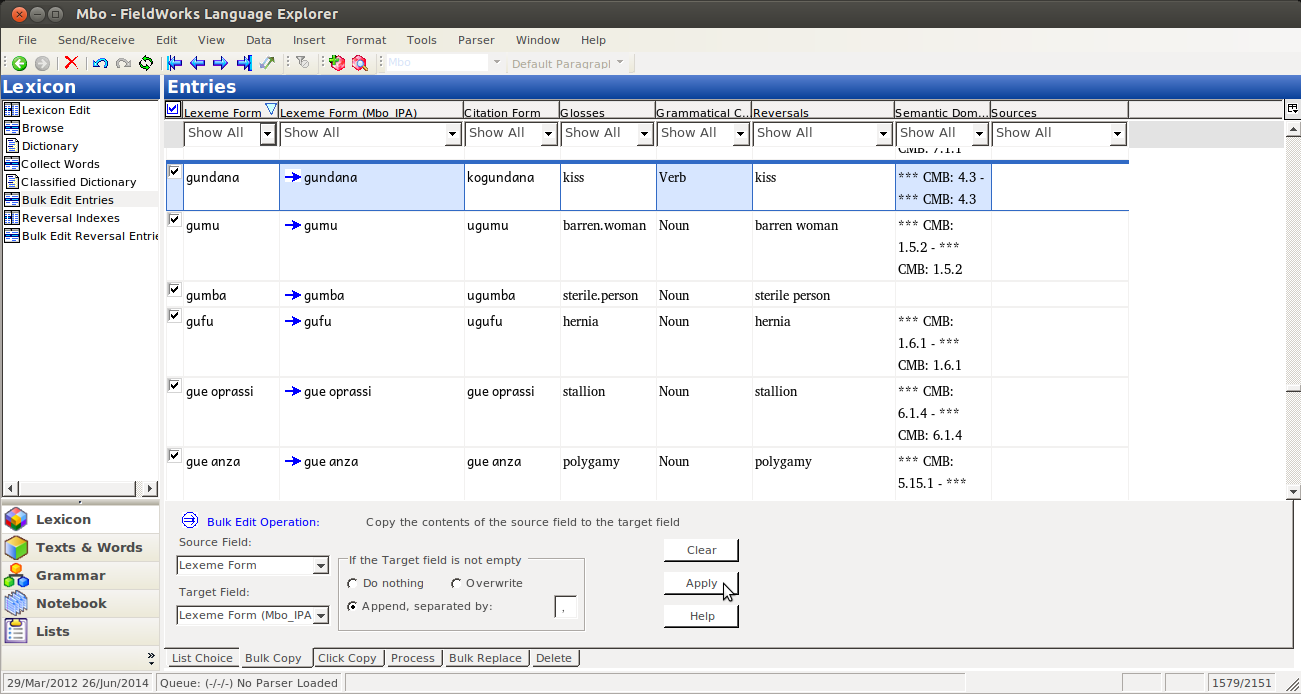
If you don’t like what you see, just click clear, and fix whatever was wrong. But if you like it, click Apply:
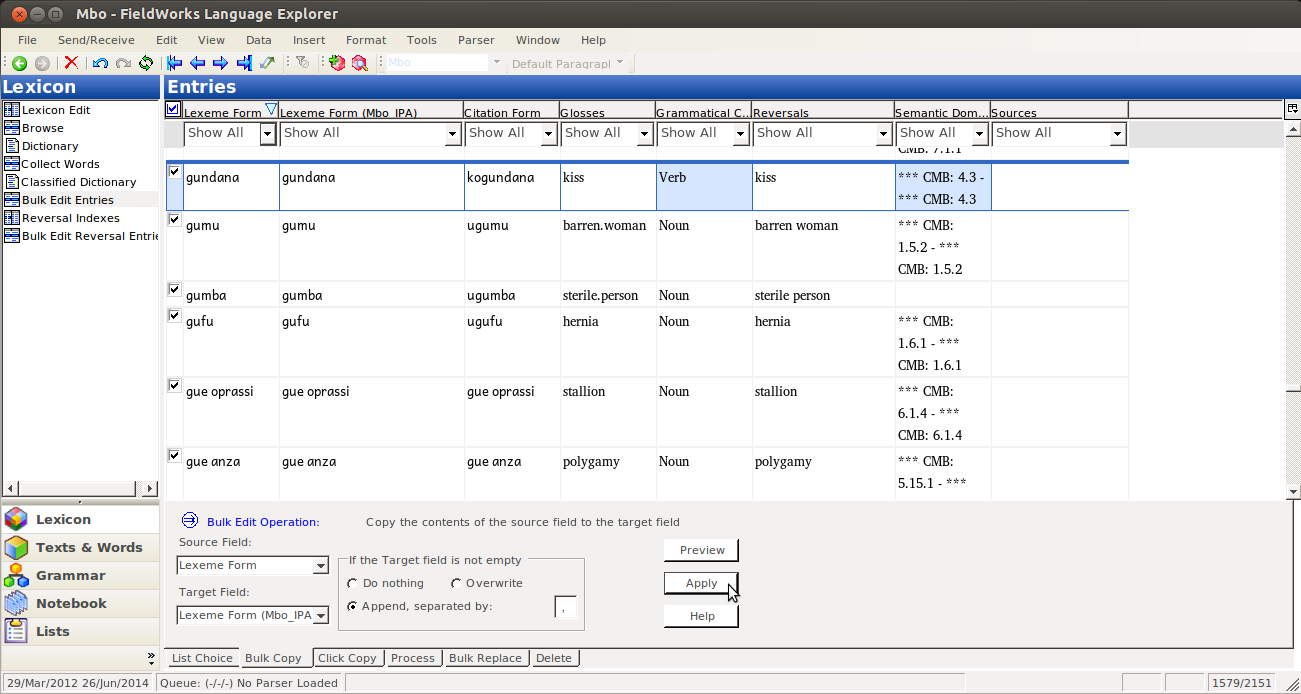
And then you’ll have both fields filled with the same data (and no more blue arrows):
But if you select data in the IPA field, the indicator above will show that the data is NOT in IPA, but still in the other writing system:
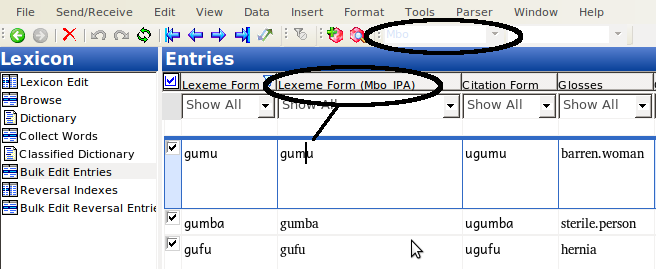
So this is the problem we need to fix. To do this, we’re going to Bulk Replace:
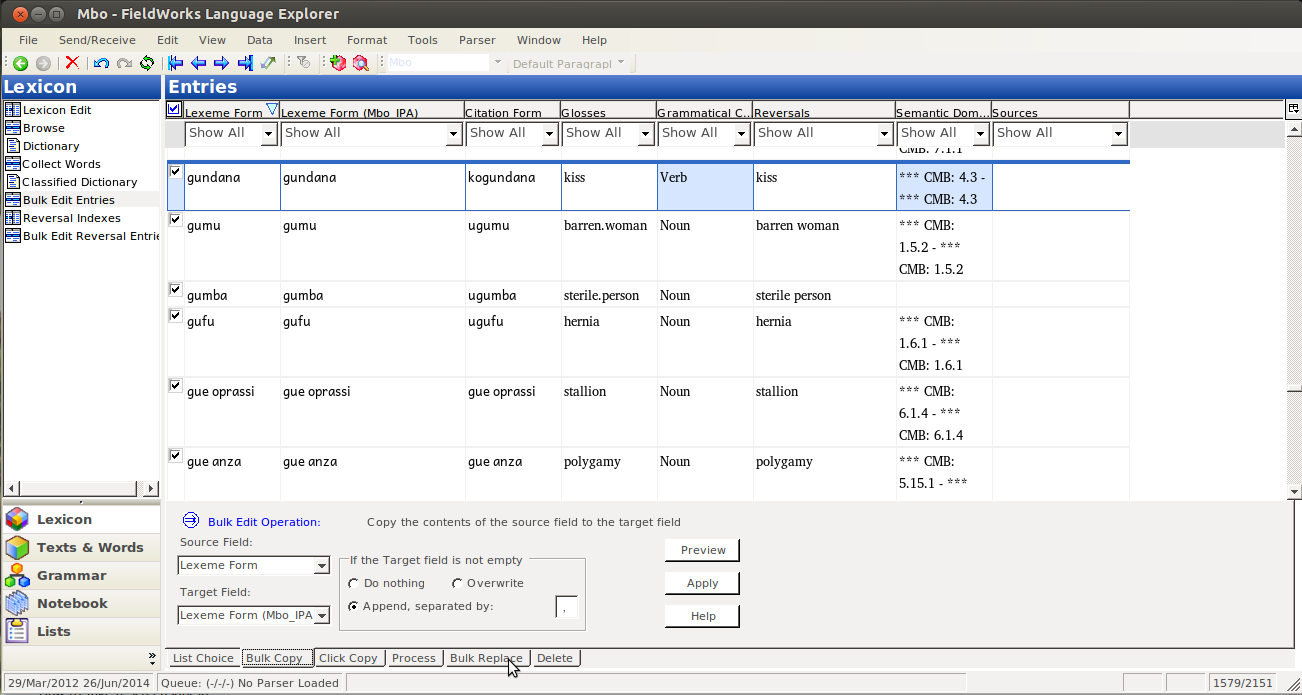
Select the target field (Just the one we want to change writing systems on, the IPA on in this case):
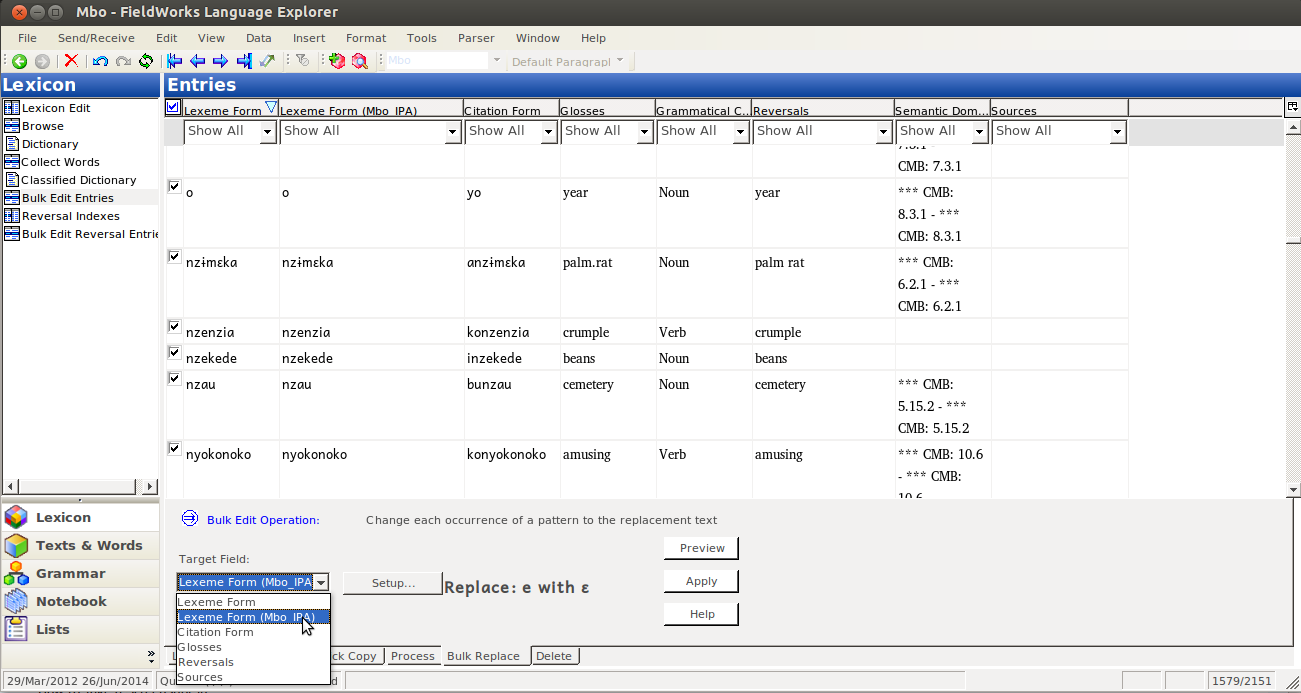
Then click on Setup…:
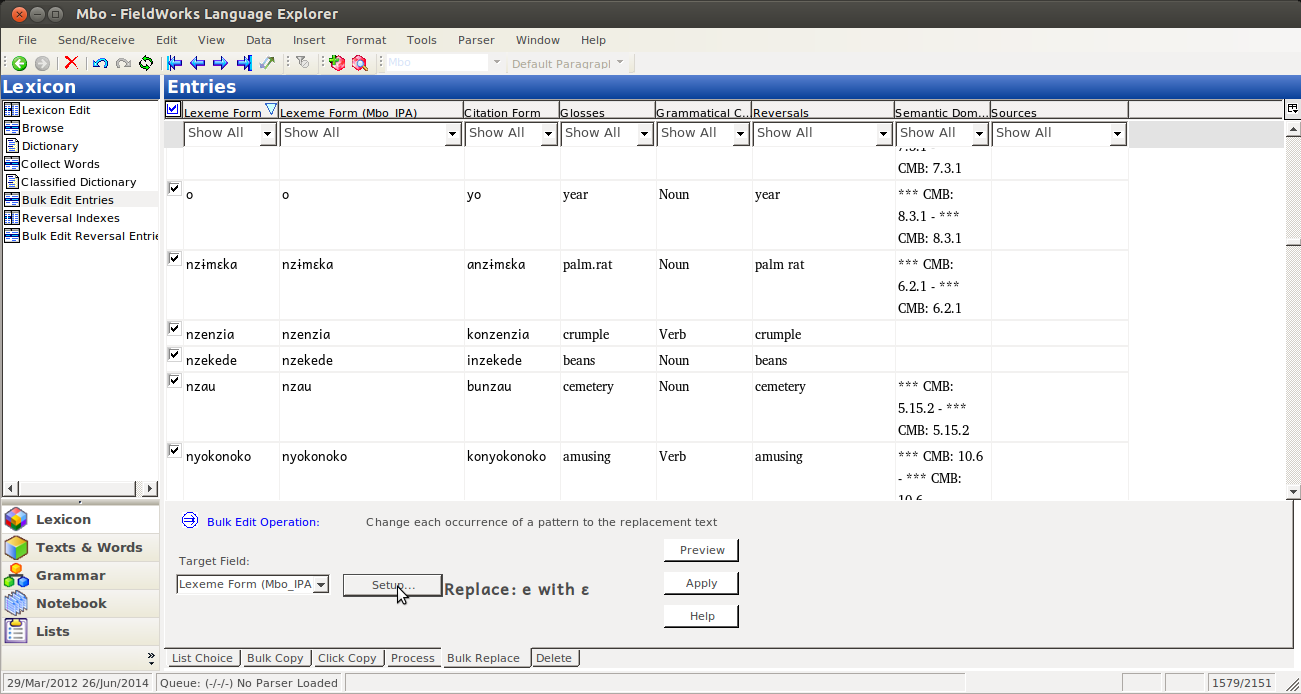
This will give you Bulk Replace Setup dialog:
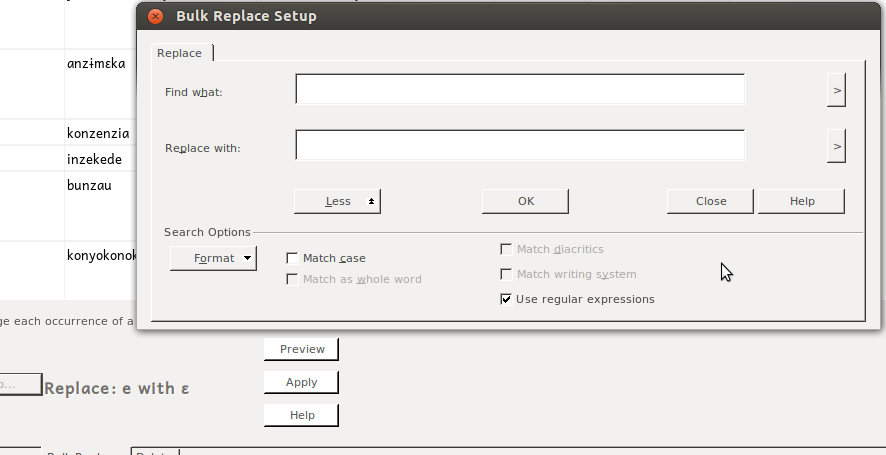
Where you can select in the “Find what:” box, then (click “more” if you have to, and) select Format/Writing System/xyz –whatever writing system you copied your data from:
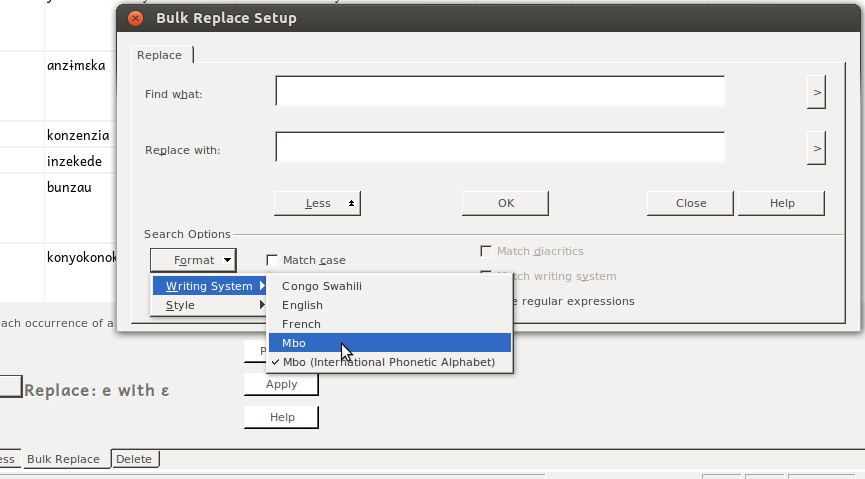
My experience is that at this point, FLEx will figure out what you’re trying to do, and set the other field for you. You can verify this by seeing “Format: <Writing system name>” under each field:
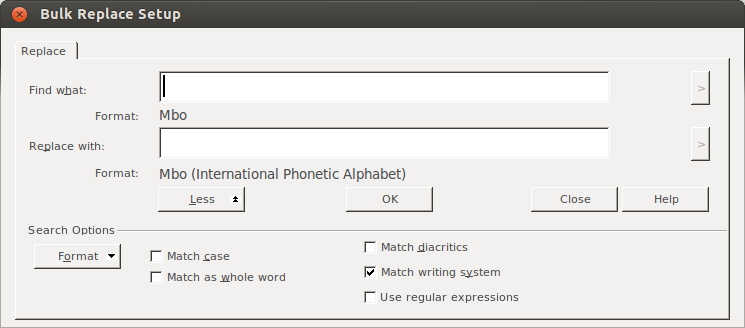
You don’t need to add anything to the empty fields in this box; you want to find everything. So you can just click OK. Unfortunately, I don’t see anything when I click “Preview” here, so we just trust that we’ve set it up correctly (you backed up your data before starting this, right? If not, stop and do it now.), and hit Apply.
Back in the bulk replace field, we can verify that the data in the IPA field is now indicated as IPA:
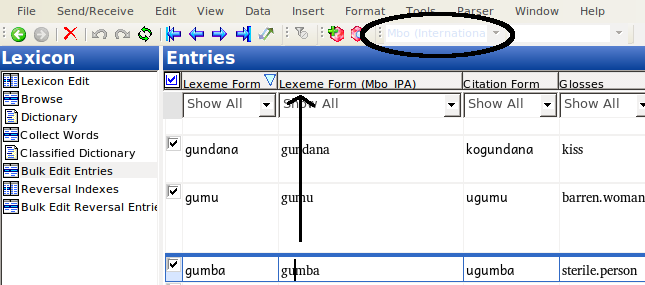
While the orthographic field is still in the orthographic writing system:
At this point, you can go through your IPA field and convert orthographic letters to IPA equivalents, either systematically through bulk replace (if appropriate) or manually. Then you can enjoy your dictionary database with both orthography and IPA in your entries!