I Think I finished a new feature today, complete with a settings page for the user to make it work.
The question of segment interpretation has been an issue almost everywhere I’ve worked, and it is often a highly idiosyncratic (or language specific, as you like) thing. So I’ve set out four boolean settings (yes/no, True/False), which govern whether a given segment type is treated as a regular consonant, or separately from other C’s, in the syllable profile analysis:
- N – Nasals, generally (or only word finally)
- G – Glides/semivowels
- S – Other sonorants (i.e., not the above)
In addition to this setting, there are also some segment combinations that could be treated separately:
- NC – Nasal-Consonant sequences
- CG – Consonant-Glide Sequences
That’s all for now, but the infrastructure is there, so if anyone REALLY needed something else, we could talk about it.
The following slides show the options for syllable profiles, after analysis given the settings as on the page (which shows current settings on open).
Default Operation
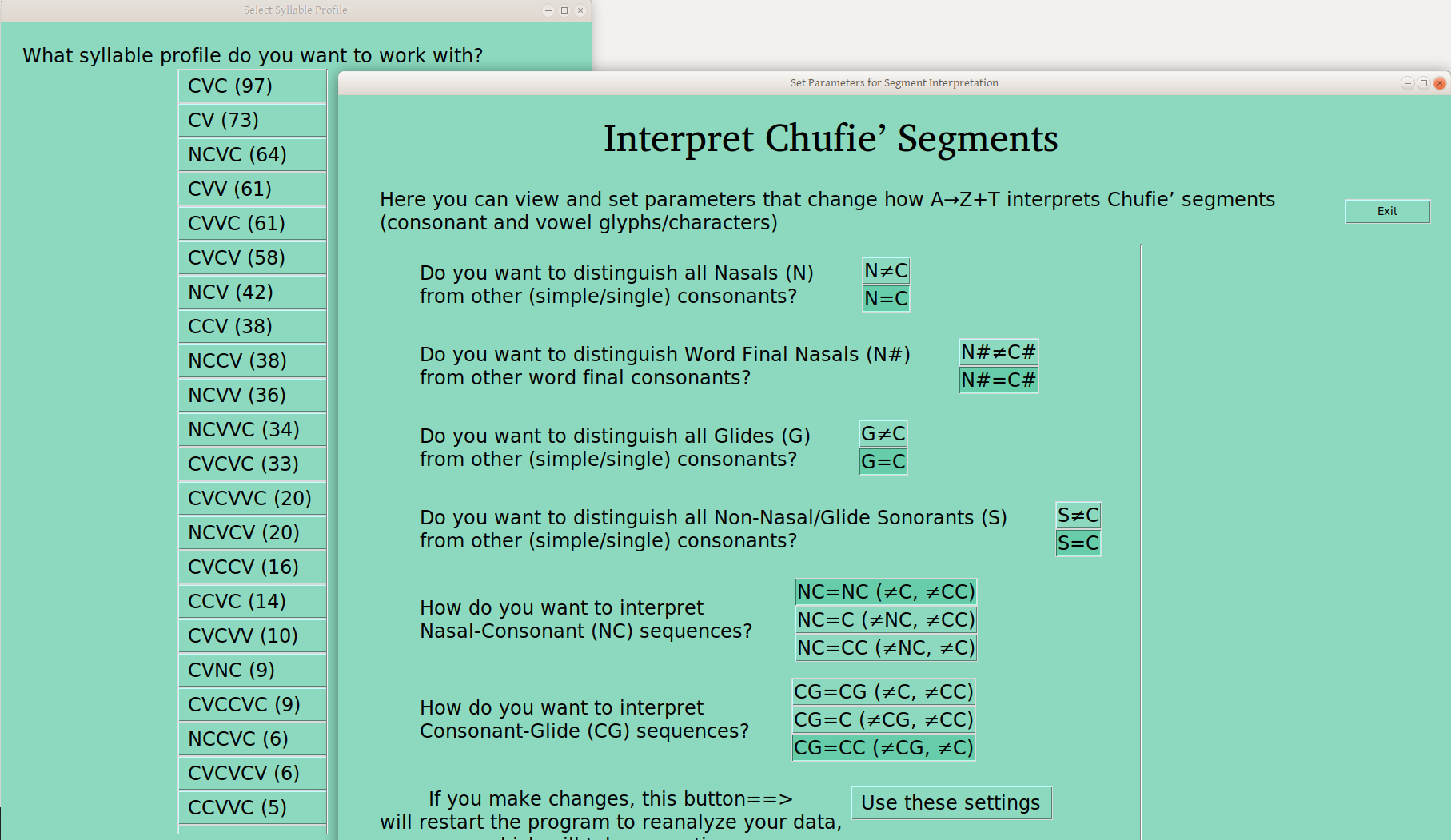
On first open, everything is a C, and no CC sequences are collapsed:

Note the number of each syllable profile, which are sorted with the largest on the top, and how quickly they taper off. I’ve always appreciated being able to do a quick syllable profile analysis, so this is nice. Good to know which are your more canonical forms (e.g., CVC and CCV here) and which are not (e.g., CCVCCV and CVCCCV here).
Distinguishing Segments by Type
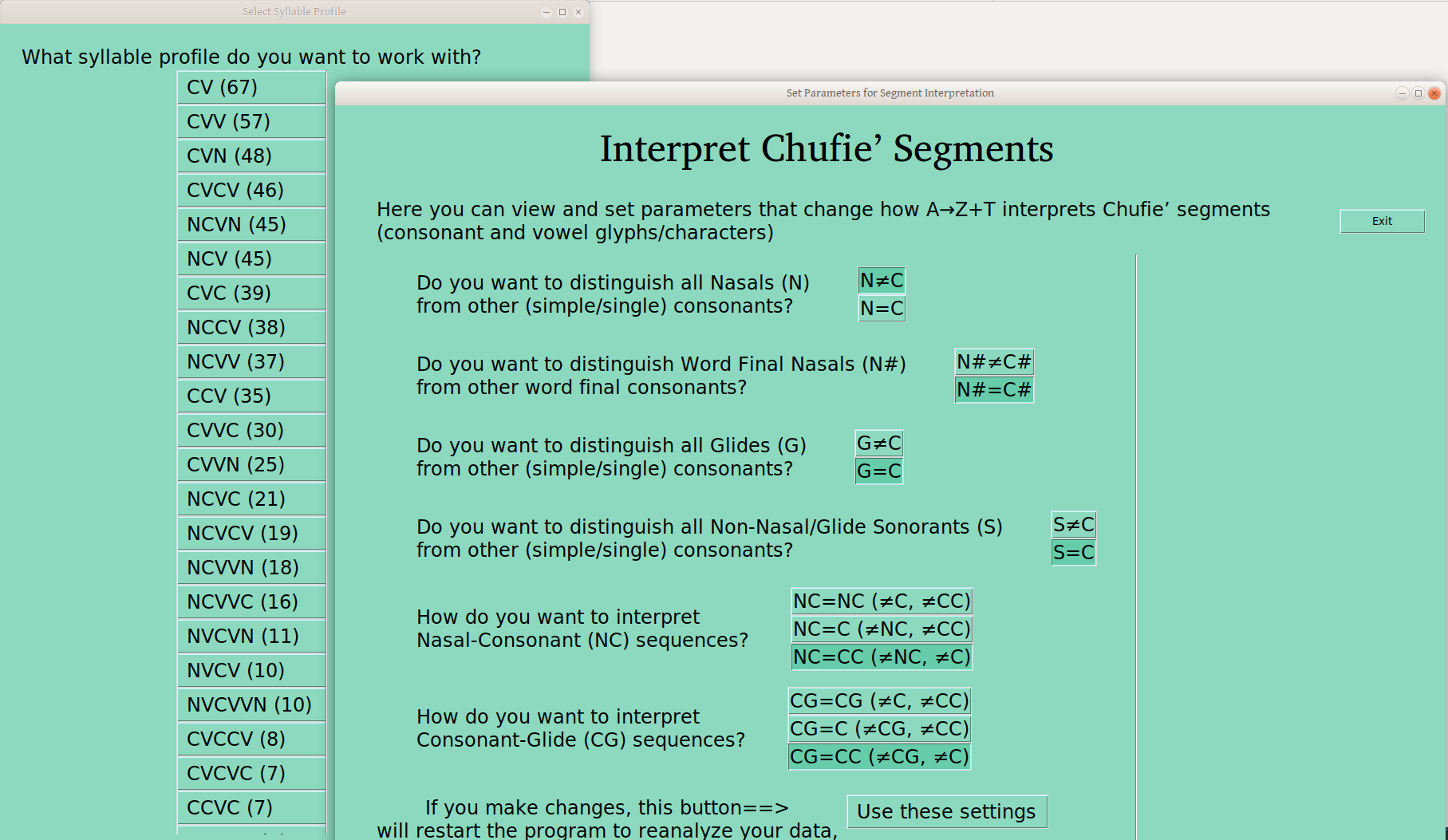
By toggling the various settings (then hitting “Use these settings”, after noting the warning that this will trigger a data reanalysis), you can get other analyses. For instance, if you set N≠C, then you get the following (All nasals are distinct from other consonants, wherever they appear):
Or, you can just distinguish nasals only word finally: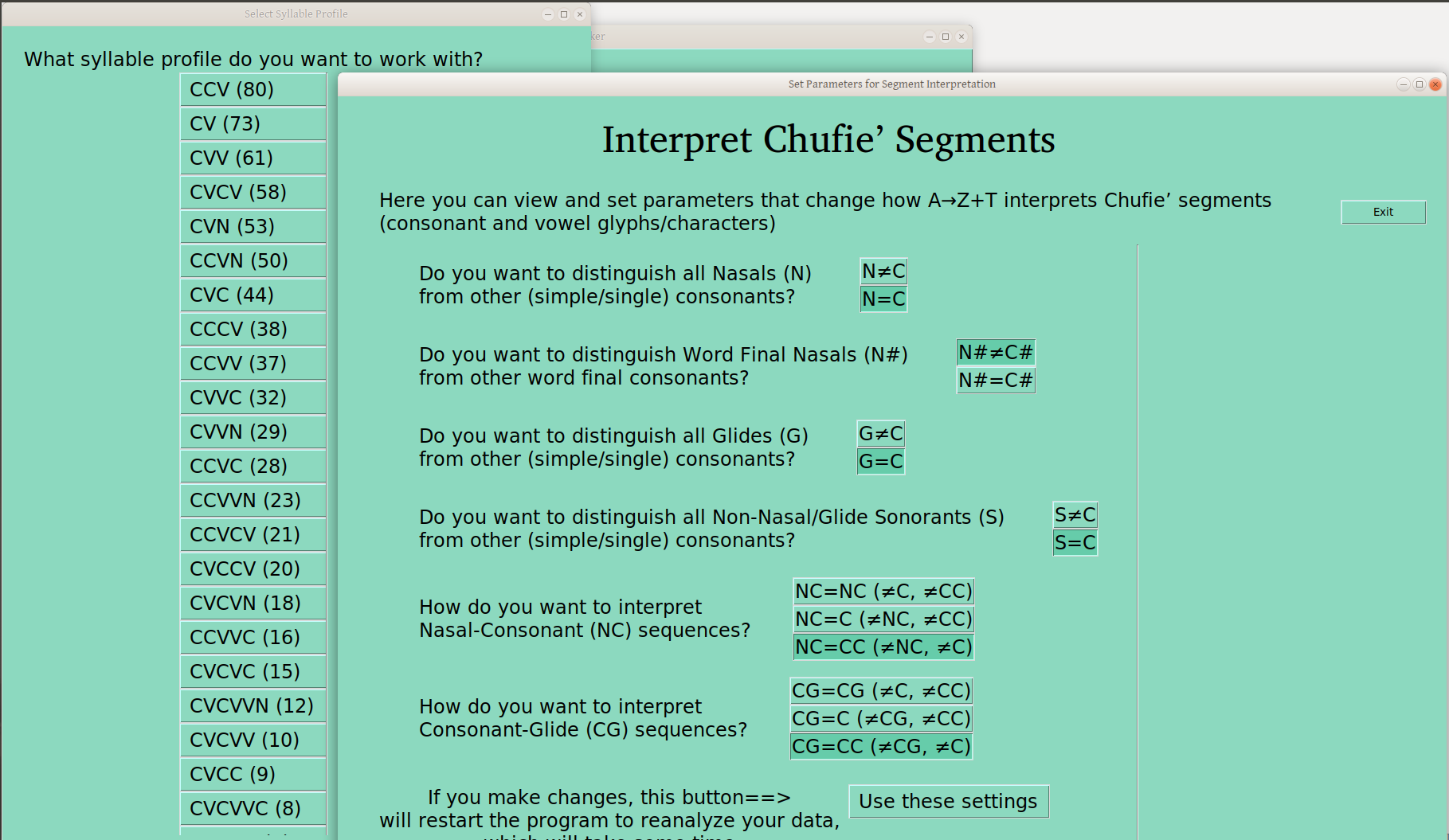
In case it isn’t obvious, there is a clear practical trade off to these selections. That is, the more distinctions you make, the smaller your groups become, from max 97 in this case, to 80 or 67, as the number of distinctions increase. So one is typically advised to use the distinctions important in the language (as soon as those are known!), and keep everything else together —hence the number of distinctions I’m offering.
And of course, you can distinguish both glides and nasals at the same time:
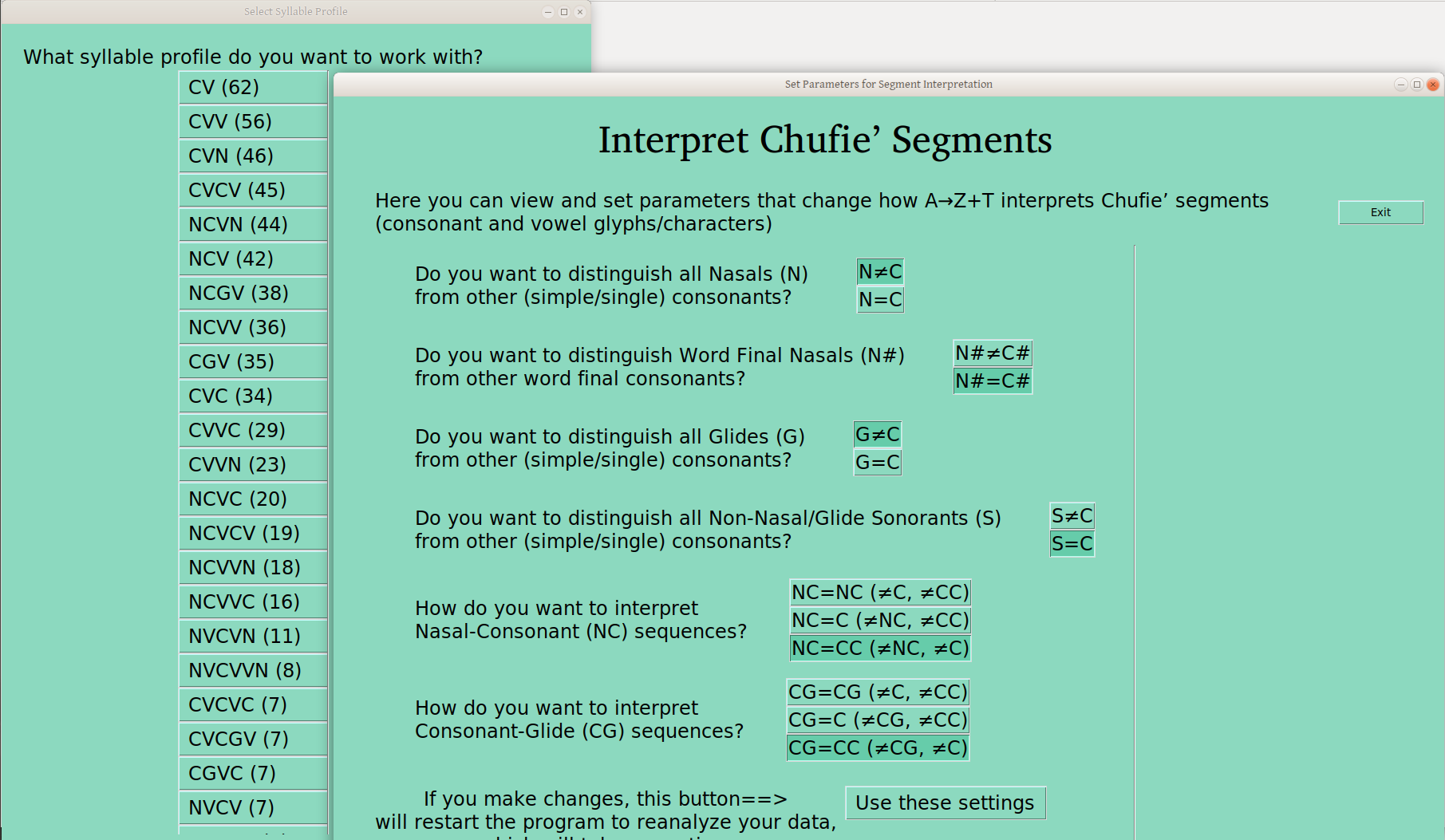
And even sonorants, too:

Distinguishing Sequences of Segment Types
The other kind of setting on this page has to do with sequences of particular segment types. That is, should NC be interpreted as such, the same as other CC sequences, or as a single C (all of which I’ve heard people want)? One advantage of this setting is that one can get NC sequences marked as such, without otherwise distinguishing nasals (as in the first two settings):
One can do the same for CG, resulting also in NCG sequences in syllable profiles:
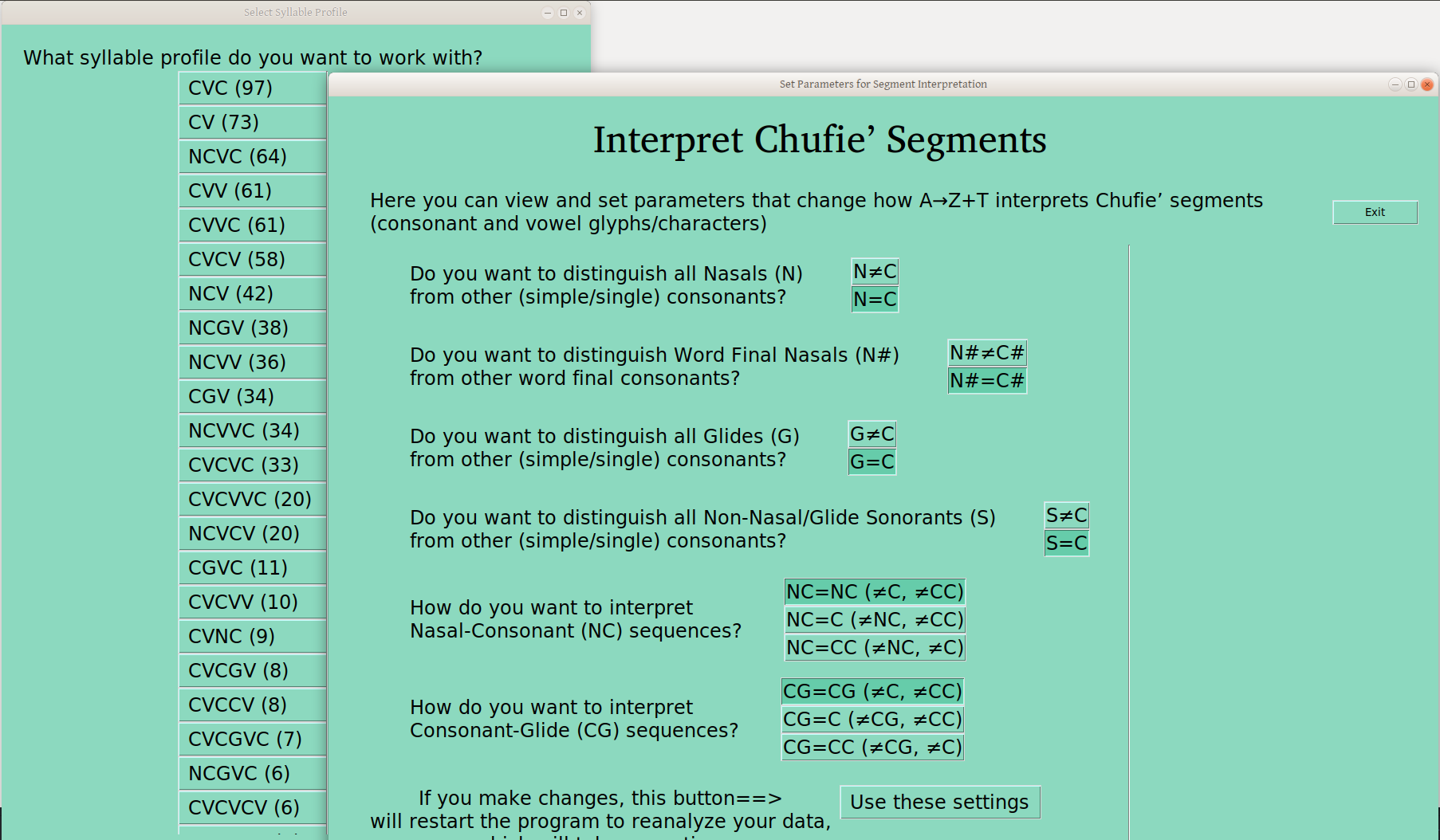
For these two settings, one can leave the default CC interpretation, or specify NC or CG as above, but one can also set either (or both) to just C, so these sequences lump together with other C’s in the profiles (I assume when appropriate for the language!), as here:
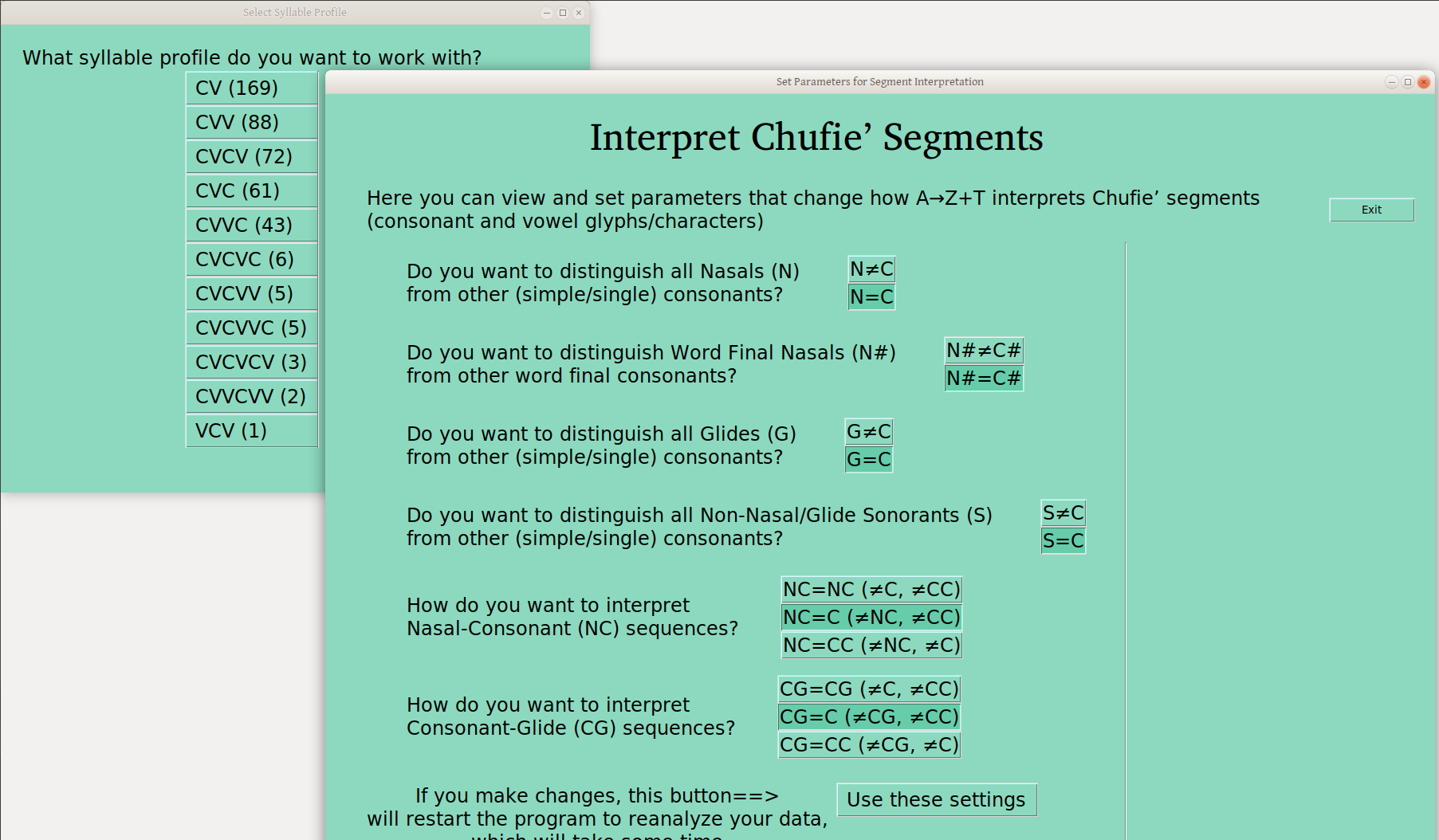
Note that this lumping greatly increases your group sizes, and reduces your number of groups, which can help a lot in the analysis —though again you want to be sure that this is appropriate. If you don’t know why it would or wouldn’t be, it probably isn’t.
Summary
Anyway, now as you go to sort words by surface tone pattern in various contexts, you can group words with certain segment types together or apart, as appropriate for the language, and work with the appropriate groups as you sort for tone. This will be available in version 0.5 of A→Z+T.