Creating Tone Fields by the Method Native to FLEx –The Better Way
(N.B.: this entry started with FW7.05~b5 and WS0.9.28, though I’m finishing it on FW7.06~b7 and WS1.1.11. Some of the screenshots may look different between these versions, but I haven’t noticed any difference in functionality with regard to these fields.)
After creating custom fields in this way for tone and plural forms, I found that tone fields are already accounted for in FLEx, though not particularly transparently. There is a set of pronunciation fields, which can be inserted here:

This option puts the set of pronunciation fields in the record you’re editing, not the whole database. It gives tone, as well as a couple other fields. It looks like this in FLEx:

What’s nice about this is that you can do this a number of times, for the same entry. This gives you the chance to have a number of pronunciations, in different contexts –which is important in phonology, especially with regard to tone. The “Location” field is an empty, customizable field, so I presume we could put things like “Before a High Tone” or “phrase finally” or whatever there, then know that that pronunciation is valid for that context. Filling in some bogus data, we see the following in FLExː

Under the Hood
The above results in the following in the appropriate entry of the LIFT file:
<pronunciation>
<form lang=”gey”><text>ba</text></form>
<field type=”cv-pattern”><form lang=”en”><text>CV</text></form>
</field>
<field type=”tone”><form lang=”en”><text>?H</text></form>
</field>
</pronunciation>
<pronunciation>
<form lang=”gey”><text>bad</text></form>
<field type=”cv-pattern”><form lang=”en”><text>CVC</text></form>
</field>
<field type=”tone”><form lang=”en”><text>?HF</text></form>
</field>
</pronunciation>
So each pronunciation has a form/text set of nodes, and fields with type attributes for each of the visible fields with data in FLEx. Note that these fields are formatted exactly the same as the fields we created earlier here and here, that is
<field type=”NameofFieldinFLEx”>
<form lang=”LanguageCode”>
<text>Field Contents</text>
</form>
</field>
The only difference here is that the fields are under a <pronunciation> node, and not directly under the entry itself. But the fact that these fields are grouped together under repeatable pronunciation nodes should mean that we can organize contextually dependent pronunciation (tone or segmental) fields.
Sorting on Pronunciation Fields
I tried sorting on individual pronunciation nodes in FLEx, but wasn’t immediately impressed. I tried sorting the above fields for those with CVC in the cv-pattern, and this is what I got:

One can see that the entry is filtered, not the set of pronunciation fields. When working with Toolbox, it was possible to filter on either of a repeated field within an entry. Recalling that this was only when sorting on that field (therefore producing a record for each of the multiple fields), I tried that in FLEx, and it worked:

Note that there is only one pronunciation field listed, and the pronunciation form and tone fields listed are those that correspond to the CV field that was selected in the filter.
This data structure would also allow one to select only particular tone patterns, such as with an XPath expression like pronunciation[/field[@type=’cv-pattern’]/form/text = ‘CVC’]/field[@type=’tone’]/form/text to get the information in the tone field under only those pronunciation nodes that also have CV fields with ‘CVC’ in them.
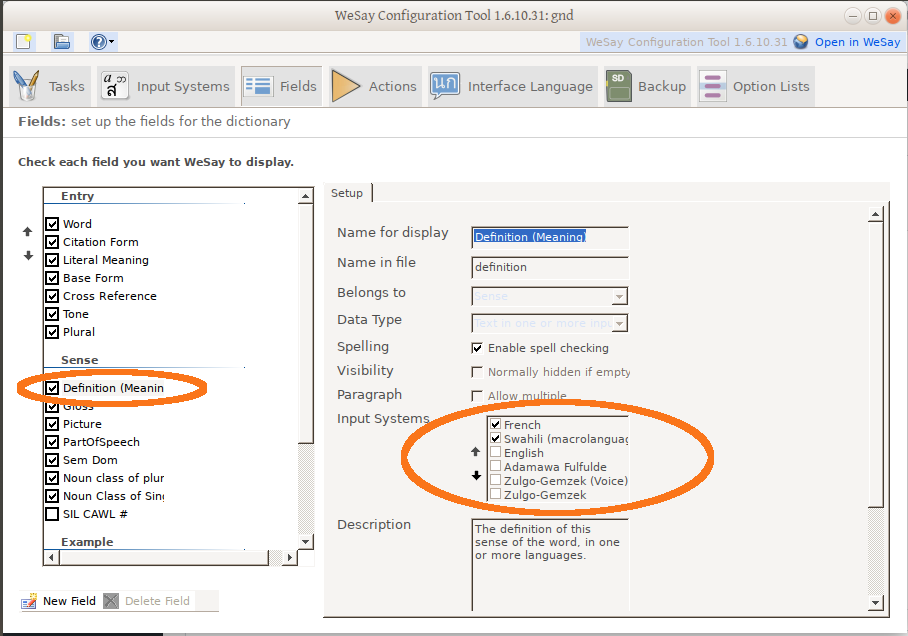
Unfortunately, I haven’t been able to see these fields in WeSay (yet, I hope: see this bug report). Which is sad, because this is otherwise the best way to indicate tone in FLEx.
===Poetic Interlude===
I wrote most of the above several months ago, and had forgotten that I had worked this much out, until I ran into the problem of bulk editing on these fields. A quick Email to <Flex_Errors at sil.org>, and a fairly rapid response later, and I was back in business. When I went to write it up, I found the above in my drafts folder…
===End of Interlude===
So I’ve been doing a lot of data collection in the last couple months using the above paradigm, keeping different tone fields separate by their sibling location fields. I have XSL transforms to add this data to a LIFT file, and some reports to pull it out later, but how to mess with it in the mean time, should I need to? To get bulk editing on these fields to work, I needed two things:
- to sort on ‘pronunciation’ or one of it’s children (this I had apparently already figured out, but forgotten)
- to select the right columns for viewing in the bulk edit view.
Selecting the right columns for viewing in the bulk edit view
In case it isn’t obvious, the visible columns in the bulk edit view determine what fields you can act on. If “Lexeme” isn’t visible, you can’t copy to or from it, or modify it with a regular expression. So first, you need to make the fields you’re looking for visible, which is done through a dialog you can access by clicking in the upper right corner, with tooltip “Configure which columns to display”:

When you click on this, you get a menu of a number of (recently selected?) fields. To access other fields, to change column ordering, or to select language options, select “More column choices…” at the bottom:

This gives you access to the following dialog, where you can find fields not on the above list, select which of a number of writing systems you want to see (and therefore Bulk Edit). The Arrows on the right allow you to move the fields up and down (moving columns left and right on the Bulk Edit screen):

One trick that may not be obvious is that the ‘Tone’ field under ‘Pronunciation’ is available here as ‘Tones’. I presume this is because there are potentially a number of different Tone fields (as in my case). This is the same for ‘Location’ > ‘Locations’ and ‘CV Pattern’ > ‘CV Patterns’.
Sorting on Pronunciation Columns
Once all the fields you’re interested in are in the “current columns” (right) side of that dialog, you can select a column to sort on (showing light blue triangle). Selecting ‘Pronunciations’ gives three lines for this entry, and proclaims “Pronunciation” at the top of the page for slower ones like me.

If you’re in a context where you want to sort on two of these fields (if one doesn’t uniquely sort them, as the screenshot above), you can select one, then shift-select another, which will give a secondary sort (and a smaller triangle) as in the following:

Here the location is the first sort, then the tone. Note that the pronunciation form isn’t sorted (a…z…k…a), though the duplicate HAfter-sg field for titi is (correctly) showing up as another pronunciation/tone field (with pronunciation/form atíti nɛ) –showing that sorting by any of the pronunciation fields gives this layout.
Bulk Editing Pronunciation Fields
Getting back to the point of it all (for me, anyway), with this configuration it is now possible to bulk copy to/from these fields:

Locations didn’t show up for me under “Bulk Replace”; I’m not sure why, though that sounds familiar –perhaps I didn’t configure it right, or maybe that’s a bug.
Summary
Though tone fields created under pronunciation fields is not currently helpful for WeSay collaboration, it seems a much more principled way of treating tone data in FLEx, since it natively allows for varied contexts, CV patterns, segmental morphophonemics impacting the frame (since each pronunciation field has a form field, which can include the lexeme, frame, and any segmental interactions between them). In addition these fields are accessible to FLEx filtering and sorting, including bulk edit operations.
Given the complexity of this configuration, I would not recommend what I have described to the computer non-savvy (e.g., users more comfortable in WeSay). But for those comfortable manipulating these configurations, FLEx can be a powerful tool for manipulating tone data.